Spoiler: Ich habe mal einen KI-Assistenten gebeten, mir eine schnelle Login-Route in Node.js zu schreiben. Das Ergebnis war funktional, kompilierte anstandslos – und enthielt eine klassische Broken-Access-Control-Lücke, die sogar OWASP auf ihrer Top-10-Liste führt. Der Assistent hatte einfach das Muster aus dem Trainings-Corpus übernommen. Herzlich willkommen im Jahr 2026, wo KI-Code-Security zum drängendsten Thema in jedem DevSecOps-Team geworden ist.
Das falsche Sicherheitsgefühl: Zahlen, die wachrütteln
Nerd-Alarm: Laut dem AI Code Security Report von Snyk glauben über 75 Prozent der befragten Entwicklerinnen und Entwickler, dass KI-generierter Code sicherer sei als menschlich geschriebener. Gleichzeitig räumen 56 Prozent derselben Gruppe ein, dass KI-Code manchmal oder häufig Sicherheitsprobleme einführt. Diese kognitive Dissonanz ist kein Randphänomen – sie ist das Kernproblem der KI-Code-Security in 2026.
Noch drastischer: Nur zehn Prozent der Befragten scannen den Großteil ihrer KI-generierten Code-Snippets überhaupt mit Sicherheitstools. Fast 80 Prozent geben zu, Sicherheitsrichtlinien zu umgehen, wenn sie KI-Codetools einsetzen. Das ist kein Tool-Problem. Das ist ein Mindset-Problem – und genau dort setzen spezialisierte Werkzeuge wie Snyk AI an.
Forschungsergebnisse, die Snyk-Produktchef Manoj Nair auf der RSA Conference 2026 präsentierte und die sich auf Arbeiten der Universitäten Berkeley und ETH Zürich stützen, zeigen: 40 bis 50 Prozent des Codes aktueller großer KI-Modelle ist verwundbar – besonders durch Autorisierungsfehler und Business-Logik-Bugs, die klassische statische Scanner systematisch übersehen. Im Ernst: Wer das ignoriert, baut auf Sand.
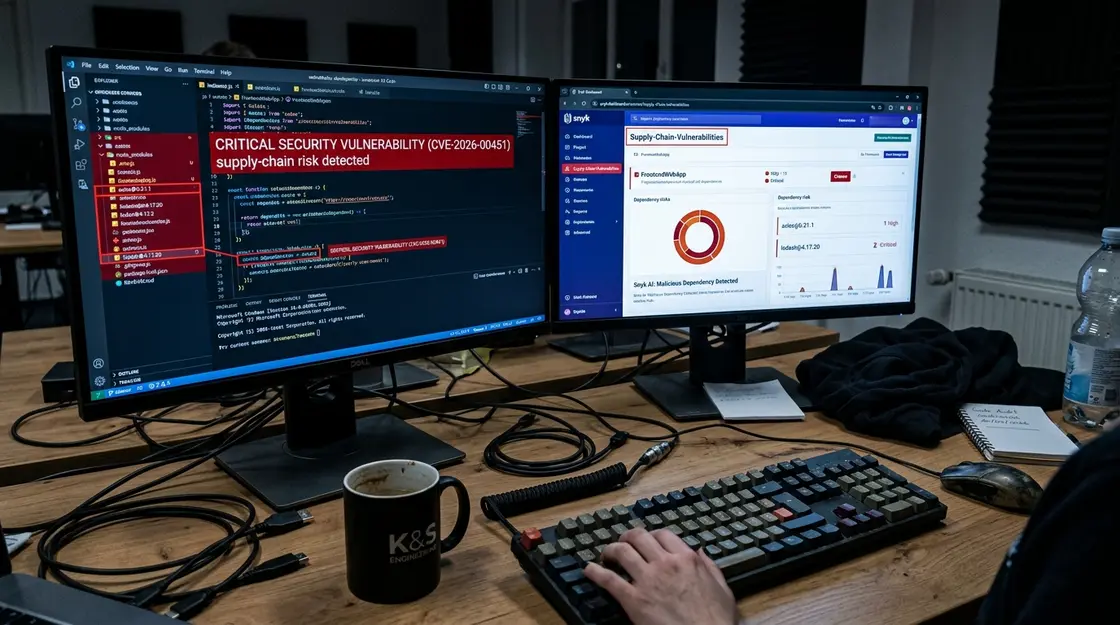
Supply-Chain-Vulnerabilities: Die Angriffsfläche explodiert
Die klassische Software-Supply-Chain kannte Dependencies, Pakete, Build-Skripte. 2026 ist diese Welt erheblich komplexer geworden. Wenn KI-Codetools im Einsatz sind, entsteht eine erweiterte AI-Supply-Chain, die Modelle, Datensätze, Prompts, Plugins, Agenten, Model-Registries, APIs und Drittanbieter-AI-Services umfasst. Jeder dieser Knoten ist ein potenzieller Angriffspunkt.
Ein konkretes Beispiel: KI-Assistenten schlagen bei der Dependency-Auswahl häufig populäre Open-Source-Bibliotheken vor – gerne in Versionen, die schon länger im Trainings-Corpus auftauchen und deshalb bekannte CVEs mitbringen. Weniger als 25 Prozent der Entwicklungsteams setzen Software Composition Analysis gezielt ein, um genau diese Supply-Chain-Vulnerabilities in KI-vorgeschlagenen Abhängigkeiten zu erkennen. Black Duck (Synopsys) dokumentiert in seiner Analyse, dass 95 Prozent der Organisationen bereits KI-Tools für die Softwareentwicklung nutzen, aber nur 24 Prozent eine umfassende Prüfung auf Sicherheit, Lizenzen, IP-Konflikte und Qualität durchführen.
Dazu kommen ganz neue Angriffsvektoren durch bösartige Plugins, Skills und MCP-Server. Nair beschrieb auf der RSA Conference 2026, dass für jedes bekannte KI-Modell etwa das Dreifache an ungeprüften Komponenten existiert – also Skills, Plugins, Tool-Connectors, die Entwickler in ihre Agenten-IDEs einbinden und die dann Zugriff auf Entwicklungsumgebungen erhalten. Dieses Bastelprojekt namens „kurz mal diesen Plugin ausprobieren“ kann sich zu einem vollständigen Kompromittierungsvektor entwickeln.
Snyk AI: Sicherheit direkt am Entstehungsort
Snyk hat sich lange als Platzhirsch bei der Dependency-Analyse einen Namen gemacht. Mit Snyk AI erweitert sich die Plattform auf KI-generierten Code und KI-native Anwendungen. Der Ansatz ist dabei bewusst auf den Entstehungsmoment ausgerichtet: IDE-Extensions analysieren Code-Vorschläge direkt beim Eintippen, bevor sie überhaupt in ein Repository gelangen.
Im Unternehmenskontext bedeutet das: Policy-Enforcement durch die IDE selbst. Teams können festlegen, welche Libraries überhaupt vorgeschlagen werden dürfen, welche Lizenzmodelle zulässig sind und welche Sicherheitsregeln für KI-generierten Code gelten. Das klingt nach Kontrolle – und ist es auch, zumindest auf dem Papier.
Meine persönliche Einschätzung dazu: Snyk AI ist kein Allheilmittel, sondern ein sinnvoller Baustein. Die Plattform ist gut darin, bekannte Schwachstellenmuster zu erkennen und in CI/CD-Pipelines zu integrieren. Was sie nicht kann: Business-Logik-Fehler im vollständigen Anwendungskontext verstehen. Dafür braucht es weiterhin erfahrene Entwicklerinnen und Entwickler, die KI-Vorschläge nicht blind übernehmen.
Tabnine Secure und der Enterprise-Ansatz
Tabnine positioniert sich mit seiner Secure-Variante explizit als datenschutzfreundliche Alternative für Unternehmensumgebungen. Der Kernversprechen: KI-Code-Generierung, die ausschließlich auf intern zugelassenen Modellen basiert und keinen Code an externe Server sendet. Für regulierte Branchen – Fintech, Healthcare, Behörden – ist das ein ernstes Kaufargument.
Interessant ist der Policy-as-Code-Ansatz: Sicherheitsregeln werden nicht als Checkliste für Entwickler formuliert, sondern als maschinenlesbare Regeln in die Agenten-IDE eingebettet. Der Assistent schlägt dann gar keinen Code vor, der gegen festgelegte Security-Policies verstößt. Das verlagert den Enforcement-Punkt vom Pull-Request-Review in den Moment der Code-Entstehung.
Praktisch heißt das: Wenn eine Policy vorschreibt, dass eine bestimmte kryptografische Bibliothek nicht verwendet werden darf, erscheint die entsprechende Import-Anweisung im Vorschlag schlicht nicht. Das ist deutlich effektiver als ein nachgelagerter Scan, der den Entwickler zwingt, bereits geschriebenen Code wieder zu öffnen und zu ändern.

LLM-generierte Bugs: Was klassische Scanner übersehen
Das Autorisierungs-Blindspot
Statische Analysewerkzeuge sind gut darin, bekannte Muster zu erkennen: SQL-Injection-Muster, unsichere Deserialisierung, hartcodierte Secrets. Was sie systematisch übersehen, sind Autorisierungsfehler auf Anwendungslogik-Ebene. Ein LLM, das eine REST-API generiert, lässt gerne mal den Check aus, ob der anfragende User überhaupt berechtigt ist, die angeforderte Ressource zu lesen. Funktional korrekt, sicherheitstechnisch eine Katastrophe.
Genau das ist der Grund, warum spezialisierte KI-Code-Security-Werkzeuge Verhaltensanalyse und dynamische Tests ergänzen müssen. Nair formulierte es auf der RSA Conference pointiert: Modelle sind besonders gut darin, die Art von Fehlern zu finden, die sie selbst erzeugen. Das spricht für KI-gestützte Security-Analyse, die die gleichen Muster kennt wie der Code-Generator.
Prompt Injection als Supply-Chain-Angriff
Weniger diskutiert, aber zunehmend relevant: Prompt Injection als Vorstufe zu Supply-Chain-Vulnerabilities. Ein manipulierter Datensatz oder ein vergiftetes Trainings-Repository kann dazu führen, dass ein Modell konsistent unsicheren Code für bestimmte Muster generiert – ohne dass der Entwickler es merkt. Das ist kein Science-Fiction-Szenario mehr, sondern eine reale Angriffsklasse, die unter dem Begriff Model Poisoning firmiert.
Agenten-IDEs, die auf Plugins und externe MCP-Server zugreifen, sind besonders exponiert: Ein bösartiger MCP-Server kann den Agenten dazu bringen, Code zu generieren oder Änderungen vorzunehmen, die dem Angreifer nützen. Shadow-KI – also inoffiziell genutzte Modelle, Plugins und Dienste, die unter dem Radar der Security-Teams laufen – ist hier das eigentliche Problem. Schatten-KI-Risiken sind kein abstraktes Zukunftsproblem, sondern messbar bereits in Enterprise-Umgebungen angekommen.
Von der statischen SBOM zur Agentic Governance
Jahrelang galt die Software Bill of Materials als Goldstandard für Supply-Chain-Transparenz. 2026 reicht das nicht mehr. Cloudsmith beschreibt in seinem aktuellen Leitfaden für Software-Supply-Chain-Security, dass eine statische SBOM nicht mehr ausreichend ist, wenn KI-Modelle, Agenten und deren Artefakte ins Spiel kommen.
Was jetzt gebraucht wird, ist eine kontinuierlich aktualisierte Übersicht über alle Artefakte: nicht nur Source-Code-Dependencies, sondern Modell-Gewichte, Datensätze, Prompt-Templates, Plugin-Versionen. Manche diskutieren das unter dem Begriff AIBOM – einer AI-spezifischen Erweiterung der SBOM. Signaturen, Provenance-Nachweise und Policy-gesteuerte Freigaben entlang der gesamten Pipeline werden zum notwendigen Standard.
Das klingt nach einer Menge Overhead – und das ist es auch. Aber der Vergleich ist ernüchternd: Ein Unternehmen, das KI-Code ohne Governance einsetzt, hat im Grunde eine Supply-Chain, die es nicht überblickt. Das ist keine Risikoabwägung mehr, das ist blinder Fleck.
Shift-left war gestern: Shift-everywhere ist das neue Ziel
Der klassische Shift-left-Ansatz bringt Security früh in den Entwicklungszyklus. Mit Agenten-basierter Entwicklung reicht das nicht mehr. Wenn ein Agent autonom Code schreibt, Abhängigkeiten installiert und Pull Requests erstellt, muss Security an jedem Punkt greifen: beim Vorschlag in der IDE, beim Commit, beim Build, beim Deployment – und zur Laufzeit.
Checkmarx ordnet in seiner Übersicht der besten KI-Code-Security-Lösungen 2026 Werkzeuge wie Snyk AI als zentrale Bausteine ein, betont aber ausdrücklich: Tooling allein wirkt nicht. Erst die Kombination aus SAST, SCA, Secret-Scanning, IaC-Scanning und verpflichtenden PR-Checks schließt die Lücke, die KI-generierter Code öffnet.
Meine zweite persönliche Meinung an dieser Stelle: Wer glaubt, ein einzelnes Security-Tool kaufen zu können und damit die KI-Code-Security-Frage zu beantworten, unterschätzt das Problem fundamental. Die Werkzeuge sind gut, aber sie ersetzen keinen strukturierten DevSecOps-Prozess, in dem Sicherheit als gemeinsame Verantwortung von Entwicklung, Security und Operations gelebt wird.
Lizenz-Compliance: Das unterschätzte Risiko
Nerd-Alarm für alle, die Lizenz-Compliance für ein juristisches Randthema halten: KI-generierter Code kann Lizenzkonflikte reproduzieren, die im Trainings-Corpus vorhanden waren. Ein Assistent, der Code aus einem GPL-lizenzierten Projekt in einem proprietären Produkt vorschlägt, schafft unter Umständen eine Lizenzpflicht, die das Unternehmen nicht eingeplant hat.
Spezialisierte KI-Code-Security-Werkzeuge prüfen deshalb nicht nur auf Sicherheitslücken, sondern auch auf Lizenz-Compliance der vorgeschlagenen Bibliotheken und – soweit möglich – auf bekannte Code-Übernahmen aus urheberrechtlich geschützten Quellen. Gerade im Enterprise-Bereich ist das kein Nice-to-have, sondern ein harter Compliance-Baustein, den CISOs zunehmend einfordern.
Die 24-Prozent-Zahl von Black Duck – also der Anteil der Unternehmen, die KI-Code wirklich umfassend auf Sicherheit, Lizenzen, IP-Konflikte und Qualität prüfen – ist hier besonders bezeichnend. Drei von vier Organisationen lassen diesen Aspekt schlicht offen. Das ist ein Bastelprojekt mit juristischen Folgekosten.
Regulatorischer Druck: Was NIS2, CRA und AI Act konkret bedeuten
Neben den technischen Herausforderungen wächst der regulatorische Druck auf Softwareentwicklungsteams spürbar. Die NIS2-Richtlinie verpflichtet Unternehmen in kritischen Sektoren dazu, Risiken in der Software-Lieferkette aktiv zu managen – was explizit einschließt, dass eingesetzte Tools und Abhängigkeiten dokumentiert und geprüft werden müssen. KI-generierter Code, der ohne Governance-Prozess in produktive Systeme gelangt, ist in diesem Rahmen ein handfestes Compliance-Problem, kein theoretisches.
Der Cyber Resilience Act der EU geht noch weiter: Produkte mit digitalen Elementen müssen künftig über ihren gesamten Lebenszyklus sicher sein und bekannte Schwachstellen zeitnah beheben. Wer KI-generierte Bibliotheken und Komponenten ohne Software Composition Analysis einsetzt, hat strukturell kaum eine Chance, diese Anforderung zu erfüllen – weil er schlicht nicht weiß, was in seiner Codebase steckt.
Der EU AI Act ergänzt das Bild um eine weitere Dimension: Für Hochrisiko-KI-Anwendungen gelten strenge Anforderungen an Transparenz, Nachvollziehbarkeit und technische Robustheit. Das betrifft nicht nur die KI-Modelle selbst, sondern auch den Code, der diese Modelle einbettet und steuert. Entwicklungsteams, die heute keine AI-SBOM und keine systematische Security-Prüfung für KI-generierten Code aufbauen, werden diese regulatorischen Anforderungen kaum rückwirkend erfüllen können.
Praxis-Szenarien: Wo Supply-Chain-Vulnerabilities konkret entstehen
Abstrakte Risikobeschreibungen helfen wenig, wenn Teams verstehen wollen, wo sie in ihrer täglichen Arbeit ansetzen müssen. Drei exemplarische Szenarien verdeutlichen das Problem:
- Szenario Microservice-Migration: Ein Team migriert einen Monolithen in Microservices und nutzt dabei einen KI-Assistenten zur Beschleunigung. Der Assistent schlägt für jede neue Service-Schnittstelle eine JWT-Validierungsbibliothek vor – in einer Version, die seit Monaten eine bekannte CVE trägt. Ohne SCA-Integration in die Pipeline landet diese Abhängigkeit unbemerkt in zwölf Services gleichzeitig.
- Szenario Agent-gesteuerte Datenbankmigrationen: Ein autonomer Coding-Agent erhält die Aufgabe, ein Datenbankschema anzupassen. Er installiert dazu eigenständig ein Migrationstool über einen npm-Registry-Mirror, den ein Entwickler vor Wochen als schnelleren Spiegeldienst eingerichtet hatte. Der Mirror ist inzwischen kompromittiert. Das Tool enthält Schadcode, der Datenbankzugangsdaten exfiltriert.
- Szenario Open-Source-Contribution: Ein Entwickler nutzt einen KI-Assistenten, um einen Bugfix für ein Open-Source-Projekt zu erstellen und als Pull Request einzureichen. Der Assistent übernimmt dabei ein Code-Fragment aus einer anderen Library mit inkompatiblem Lizenzmodell. Das Projekt nimmt den PR an, ohne die Lizenzherkunft zu prüfen – und zieht sich damit eine Lizenzpflicht zu, die erst Monate später in einem Audit entdeckt wird.
Diese Szenarien sind keine Worst-Case-Konstrukte. Sie beschreiben Muster, die in der Praxis entstehen, wenn Geschwindigkeit und Automatisierung ohne entsprechende Governance-Strukturen skaliert werden. Snyk AI, Tabnine Secure und ähnliche Werkzeuge können in allen drei Szenarien als Frühwarnsystem wirken – aber nur, wenn sie konsequent in jeden Schritt des Workflows eingebunden sind, nicht als nachgelagertes Audit-Werkzeug.
Was bleibt – und was zu tun ist
KI-Code-Security ist keine Nischen-Disziplin mehr. Mit 95 Prozent KI-Adoption in der Softwareentwicklung ist das Thema in jeder Codebase angekommen – ob Teams es wahrhaben wollen oder nicht. Snyk AI, Tabnine Secure und ähnliche spezialisierte Werkzeuge sind wichtige Gegenpole zur reinen Code-Generierungs-Euphorie. Sie sind aber keine Autopiloten, die das Nachdenken ersetzen.
Konkrete Handlungsschritte für Teams, die jetzt beginnen wollen: SCA in jede Pipeline integrieren und KI-vorgeschlagene Dependencies automatisch auf CVEs und Lizenzprobleme prüfen. Policies für zugelassene Modelle, Plugins und MCP-Server definieren – und in der IDE durchsetzen. Ein AI-Asset-Register aufbauen, das Modell-Versionen, Datensätze und Plugin-Dependencies nachvollziehbar macht. Dynamische Tests und Verhaltensanalyse für Agenten-Anwendungen einplanen, weil statischer Code-Scan allein dort nicht greift.
Welche Supply-Chain-Vulnerabilities in Ihrem Unternehmen gerade durch KI-generierter Code unbemerkt eingebracht werden – haben Sie eine Antwort darauf?



Was halten Sie von dem Thema? Hier können Sie mit anderen Leserinnen und Lesern ins Gespräch gehen.
Mitreden & diskutieren
Ihre Meinung zählt — teilen Sie Gedanken, Fragen oder Erfahrungen zu diesem Artikel.