
Ich gebe es zu: Mein erster Versuch, Ollama auf einem Raspberry Pi 4 mit 4 GB RAM zu betreiben, endete mit einer Swap-Katastrophe, einem heiß gelaufenen Kühlkörper und dem leisen Seufzen des kleinen Boards, das mir unmissverständlich mitteilte, dass 7-Milliarden-Parameter-Modelle hier definitiv fehl am Platz sind. Spoiler: Der Raspberry Pi 5 mit 8 GB RAM erzählt eine andere Geschichte – und die Container-Stacks, die gerade für Edge-Inference optimiert werden, machen lokale KI-Modelle im Wohnzimmer endlich realistisch.
Warum der Raspberry Pi plötzlich als KI-Hub ernst genommen wird
Lange galt der Raspberry Pi als Bastelprojekt-König für LED-Strips und Wetterstation-Displays. Aber seit dem Pi 5 hat sich die Ausgangslage fundamental verschoben. Der Broadcom BCM2712 mit vier ARM Cortex-A76-Kernen bei 2,4 GHz bringt nach Herstellerangaben rund zwei- bis dreifach mehr CPU-Leistung als der Pi 4 – und das PCIe-2.0-Interface macht NVMe-SSDs möglich, was für Modell-Storage entscheidend ist. Mit 8 GB LPDDR4X-RAM ist der Pi 5 kein Spielzeug mehr.
Hinzu kommt eine Entwicklung auf Software-Seite, die im Frühjahr 2026 richtig Fahrt aufgenommen hat: Container-Runtimes wie Ollama und LocalAI liefern zunehmend ARM64-optimierte Builds, die auf dem Pi 5 direkt aus der Box laufen. Gleichzeitig schieben Modellanbieter kompakte Varianten nach – quantisierte Sprachmodelle im 1-bis-3-Milliarden-Parameter-Bereich, die mit 4-bit-GGUF-Format den RAM-Bedarf auf unter 2 GB drücken. Das ist der Punkt, an dem lokale KI-Modelle auf dem Pi vom Nerds-only-Experiment zum echten Heimserver-Dienst werden.
Nerd-Alarm: Die Kombination aus Pi 5, Raspberry Pi OS auf Debian 12 „Bookworm“ (dem aktuellen offiziellen Stand seit 2023), Docker Engine und einem Inference-Container ergibt einen Stack, den man legitim als privaten KI-Hub bezeichnen kann. Ohne Cloud-Abo, ohne Datenweitergabe, mit fünf bis zehn Watt Dauerleistungsaufnahme.
Was lokale KI-Modelle auf dem Pi realistisch leisten – und was nicht
Im Ernst: Hier muss ich deutlich werden, damit keine falschen Erwartungen entstehen. Wer hofft, GPT-4-Niveau direkt auf dem kleinen Board zu bekommen, wird enttäuscht. Der Pi 5 mit 8 GB RAM ist für große Foundation-Modelle jenseits von 13 Milliarden Parametern in voller Präzision schlicht ungeeignet – zu wenig RAM, zu wenig Rechenleistung, keine dedizierte GPU.
Was aber tatsächlich funktioniert, ist sorgfältig ausgewählt: Sprachmodelle mit 1 bis 3 Milliarden Parametern, stark quantisiert auf 4 Bit, liefern brauchbare Reaktionszeiten. Realistisch sind fünf bis fünfzehn Sekunden pro Antwort je nach Modelllänge – kein Streaming-Feeling wie bei ChatGPT, aber für Heimautomations-Anfragen, kurze Textzusammenfassungen oder lokale Intent-Erkennung durchaus verwendbar. Whisper tiny und small als ASR-Modelle quantisiert schlagen sich auf dem Pi 5 deutlich besser, da Spracherkennung weniger RAM-intensiv ist als vollständige Sprachgenerierung. Auch Vision-Modelle mit MobileNet-ähnlicher Architektur für Kameraanalyse laufen flüssig.
Wer Ollama auf dem Pi 4 versucht, stößt schneller an Grenzen. Der ältere Cortex-A72-Core bei 1,5 GHz und die schwächere Speicherbandbreite machen selbst kompakte Modelle zur Geduldsprobe. Für reine Steuerlogik, MQTT-Broker oder Home-Assistant-Integration ist der Pi 4 weiter tauglich – als Inference-Node für lokale KI-Modelle ist der Pi 5 die klare Wahl.
Der Container-Stack: Ollama, LocalAI und Docker auf dem Pi
Welches Container-System passt wozu?
Für den Einstieg empfehle ich Docker Compose auf einem einzelnen Pi 5. Das Ökosystem ist am breitesten dokumentiert, ARM64-Images sind inzwischen Standard, und für ein Heim-KI-Setup mit zwei bis drei Diensten braucht man keine Cluster-Orchestrierung. Community-Entwickler wie Vasco Guita haben speziell für Pi-Homelabber saubere Raspberry-Pi-OS-Basisimages für Docker bereitgestellt, die direkt auf offiziellen OS-Images aufbauen und sauberere Container-Deployments als generische Debian-Images ermöglichen – wichtig: das ist ein Community-Projekt, kein offizielles Produkt von Raspberry Pi Ltd.
Für alle, die mehrere Pis haben und Lastverteilung wollen, kommt Docker Swarm ins Spiel. Praxisberichte aus der Homelab-Szene zeigen, dass Docker-Swarm-Cluster auf Pi-Hardware mit `docker stack deploy` für KI-Microservices und Proxy-Setups stabil funktionieren. LXD und LXC sind eine interessante Alternative – Canonical bietet ein LXD-Appliance-Image für Raspberry Pi 4 an, und in der Linux-Containers-Community werden Pi-Cluster-Setups mit LXD aktiv diskutiert. Für KI-Workloads ist Docker aber weiterhin die praktischere Wahl, weil die Inference-Container von Ollama und LocalAI primär als Docker-Images gepflegt werden.
Kubernetes auf dem Pi – also k3s oder MicroK8s – klingt verlockend, ist aber Overkill für Setups mit ein bis drei Boards. Der Overhead frisst RAM, den man lieber dem Sprachmodell gönnt. Kubernetes lohnt sich erst bei vielen Nodes und komplexer Multi-Service-Orchestrierung.
Ollama vs. LocalAI: Zwei Philosophien, ein Ziel
Ollama setzt auf Einfachheit: Ein Befehl, Modell lädt herunter, REST-API verfügbar. ARM64-Builds für den Pi existieren, und die OpenAI-kompatible API macht die Integration in bestehende Heimautomations-Setups unkompliziert. LocalAI geht einen anderen Weg – der in Go geschriebene Inference-Server unterstützt verschiedene Backends (ggml, gguf), läuft als schlanker Container und deckt neben Sprachmodellen auch Whisper-Varianten und Embedding-Modelle ab. Wer heterogene Modell-Typen in einem Stack bündeln will, ist mit LocalAI flexibler.
Beide Tools profitieren massiv von den neuen Tiny-Modellen, die 2025 und 2026 in großer Zahl erschienen sind. Phi-3-mini, Gemma-2 2B, Qwen 2.5 in kompakten Varianten – all diese Modelle existieren als 4-bit-GGUF-Dateien, die unter 2 GB Speicher benötigen und auf dem Pi 5 zumindest benutzbar sind. Das ist der eigentliche Durchbruch: nicht die Hardware, sondern die Modelloptimierung. Edge Computing profitiert hier direkt. Wer sich für weiterführende Raspberry-Pi-5-Projekte jenseits des KI-Bereichs interessiert, findet auf digital-magazin.de einen guten Überblick über das breite Einsatzspektrum des Boards.
Den Stack absichern: Reverse Proxy, TLS und kein offener Port ins Internet
Ein lokaler KI-Hub ohne Absicherung ist ein Bastelprojekt mit Risiko. Inference-APIs sollten niemals direkt per Port-Forwarding ins Internet exponiert werden. Der Standardweg in der Pi-Homelab-Community: Traefik oder NGINX als Reverse Proxy vor den Container-Stack schalten, TLS über Let’s Encrypt oder ein selbst signiertes Zertifikat einrichten, und Zugriff von außen nur über VPN – zum Beispiel WireGuard, das sich ebenfalls als Container deployen lässt.
Spoiler: Wer auf Watchtower setzt, bekommt automatische Container-Updates für die Inference-Engine und Modell-Wrapper, ohne manuell eingreifen zu müssen. Portainer als Web-UI macht den Stack außerdem beherrschbar, ohne dass man ständig SSH-Sessions öffnen muss. Praxisberichte aus der Homelab-Community zeigen, dass auf einem Pi 4 problemlos mehr als 50 Docker-Container parallel laufen können – Monitoring, Proxy, Datenbanken und Anwendungen zusammen. Edge Computing im Wohnzimmer hat durchaus Substanz.
Wichtig für den Betrieb: RAM-Auslastung, Swap-Rate, Inferenz-Latenz und CPU-Temperatur sind die vier Messwerte, die man im Auge behalten muss. Drosselt der Pi thermisch, bricht die Token-Rate ein. Ein aktiver Kühler – den Raspberry Pi Ltd. für den Pi 5 mitliefert – ist kein optionales Zubehör, sondern Pflicht für Dauerbetrieb unter Last.
Lokale KI-Modelle vs. Cloud: Was man wirklich bekommt
Ich finde, die Diskussion wird oft zu binär geführt: lokale KI auf dem Pi gegen Cloud-KI wie ChatGPT oder Claude. Das ist der falsche Vergleich. Ein Pi-5-Stack mit einem 3B-Modell wird GPT-4-Klasse nicht schlagen – weder in Antwortqualität noch in Geschwindigkeit. Aber darum geht es nicht.
Der echte Vorteil von Edge Computing auf dem Pi ist Datensouveränität: Mikrofon-Audio für den lokalen Sprachassistenten verlässt nie das Heimnetz. Kamera-Frames für die Eingangsanalyse werden nicht in eine Cloud hochgeladen. Intent-Erkennung für Home-Assistant-Befehle läuft offline und reagiert auch bei Internetausfall. Das sind Use Cases, bei denen ein schwächeres Modell lokal einer starken Cloud-KI überlegen ist – weil Verfügbarkeit und Privatsphäre wichtiger sind als Antwortqualität. Außerdem fallen keine API-Kosten an, was für Dauerläufer mit vielen Anfragen pro Tag relevant ist.
Edge-Inference ist deshalb kein Ersatz für Cloud-KI, sondern eine Ergänzung für spezifische Szenarien. Wer komplexe Analysen oder kreative Texte braucht, wird weiterhin auf leistungsstarke externe Dienste zurückgreifen. Wer einen privaten, immer verfügbaren Assistenten für Smart-Home-Befehle, lokale Transkription oder einfache Dokumentensuche will, hat mit dem Pi-Stack eine ernsthafte Option.
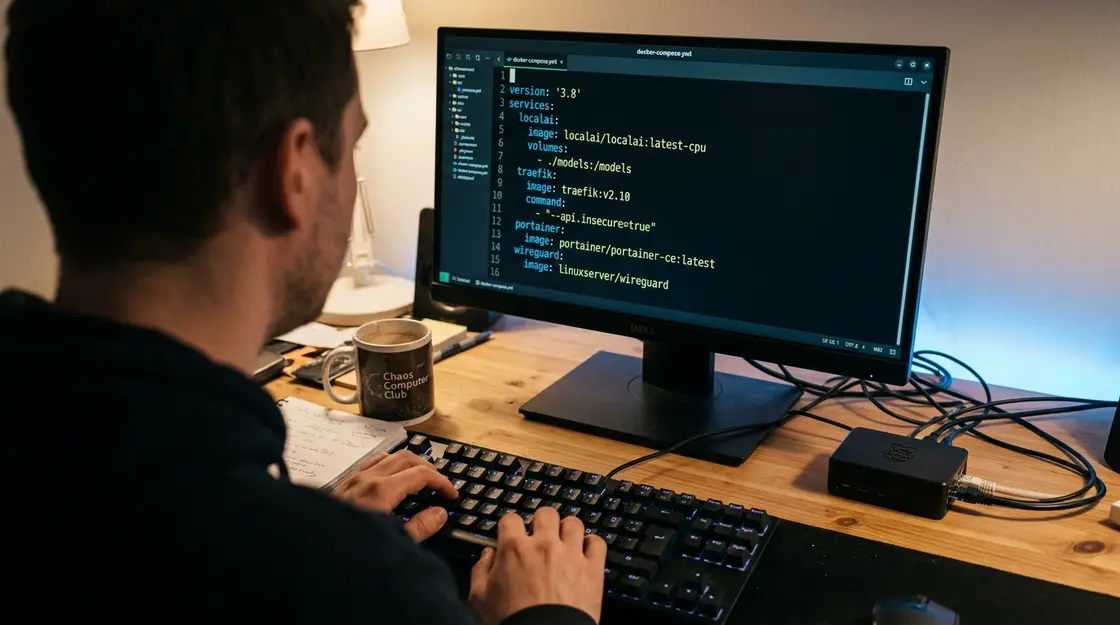
Typischer Setup-Ablauf: Pi 5, Docker, LocalAI und Traefik
Das Grundgerüst für einen lokalen KI-Hub sieht in der Praxis so aus: Raspberry Pi 5 mit 8 GB RAM, NVMe-SSD über PCIe (mindestens 128 GB für Modell-Storage), Raspberry Pi OS 64-bit auf Basis von Debian 12 Bookworm. Docker Engine aus dem offiziellen Docker-Repository für Debian-basierte Systeme installieren – nicht das veraltete `docker.io`-Paket aus den Debian-Repos, das oft eine ältere Version liefert.
Dann ein Docker-Compose-File mit vier Diensten: LocalAI oder Ollama als Inference-Container, Traefik als Reverse Proxy mit TLS, Portainer für das Container-Management und WireGuard für VPN-Zugang von außen. Modelle landen als GGUF-Dateien auf der NVMe-SSD, eingebunden als Volume. Das war’s – kein Kubernetes, keine Cloud-Abhängigkeit, kein monatliches Abo.
Für Einsteiger gibt es auf Hackster.io und in der Raspberry-Pi-Community aktive Diskussionen zu Docker-Deployments auf dem Pi, die konkrete Compose-Files und Troubleshooting-Tipps liefern. Das C-3PO-KI-Projekt, das lokale Heimassistenten auf Pi-Basis baut, zeigt außerdem, wohin die Reise geht: vollständige Voice-Pipeline mit Wakeword, ASR (Whisper), LLM-Inference und TTS – alles containerisiert, alles lokal.
Performance-Realität: Benchmarks einordnen
Nerd-Alarm: YouTube-Benchmarks zu Pi-KI-Setups sollte man immer kritisch lesen. Oft fehlen die entscheidenden Parameter: Welches Modell, welche Quantisierungsstufe, welche Eingabelänge, mit oder ohne Swap, mit oder ohne aktive Kühlung? Wer Zahlen ohne diese Angaben sieht, sollte misstrauisch sein.
Was belegte Praxiserfahrungen zeigen: Auf dem Pi 5 mit 8 GB RAM und einem 1B-Modell in 4-Bit-Quantisierung sind Inferenz-Latenzen von etwa fünf bis zehn Sekunden realistisch. Ein 3B-Modell gleicher Quantisierung braucht eher zehn bis zwanzig Sekunden. Für interaktive Chat-Dialoge im GPT-Stil ist das zu langsam; für automatisierte Heimsteuerungsabfragen, bei denen eine Sekunde Reaktionszeit tolerierbar ist, reicht es. Whisper-Transkription läuft schneller, weil ASR-Modelle in der kleinen Variante recheneffizienter sind als generative Decoder. Das Hailo AI-Kit als PCIe-Erweiterung für den Pi 5 verspricht deutlich mehr Inference-Durchsatz durch dedizierte NPU-Rechenleistung – allerdings zu zusätzlichen Kosten und mit anderen Modell-Kompatibilitätsfragen.
Mein persönlicher Eindruck nach dem Testen: Wer den Pi-KI-Stack als Sprachassistenten für smarte Heimsteuerung einsetzt und keine Echtzeit-Streaming-Antworten erwartet, wird überrascht sein, wie brauchbar das Ergebnis ist. Wer einen ChatGPT-Ersatz sucht, wird frustriert sein.
Modellauswahl und Quantisierungsstufen: Worauf man achten sollte
Die Wahl des richtigen Modells ist auf dem Pi entscheidender als auf leistungsstarker Desktop-Hardware – und hier liegt eine häufige Fehlerquelle für Einsteiger. Nicht jedes GGUF-Modell auf Hugging Face ist für ARM-CPUs ohne GPU-Offloading gleich gut geeignet. Zwei Faktoren bestimmen die Praxistauglichkeit: Parameterzahl und Quantisierungsstufe.
Als Faustregel gilt: Q4_K_M (4-Bit mit mittlerer Kalibrierung) bietet auf dem Pi 5 den besten Kompromiss aus Qualität und Geschwindigkeit. Q5- und Q8-Varianten desselben Modells liefern schärfere Antworten, aber die höhere Speicherbandbreite kostet spürbar Token-Rate. Q2-Quantisierungen sind zwar kleiner, neigen aber bei vielen Modellen zu deutlichen Qualitätseinbußen, die besonders bei komplexen Anfragen auffallen. Für den Alltagsbetrieb empfiehlt es sich deshalb, mit Q4_K_M zu starten und Abstriche erst dann in Kauf zu nehmen, wenn das Modell RAM-seitig nicht passt.
Konkrete Empfehlungen für den Pi-5-Stack: Phi-3-mini in der Q4_K_M-Variante ist ein guter Einstiegspunkt für allgemeine Sprachverarbeitung. Gemma-2 2B eignet sich besonders für strukturierte Aufgaben wie Intent-Erkennung oder einfache Klassifikation. Für Sprachtranskription ist Whisper.cpp in der tiny.en- oder base.en-Variante die effizienteste Wahl, weil das cpp-Backend auf ARM besser optimiert ist als der Python-Wrapper. Wer Embedding-Modelle für semantische Suche im lokalen Dokumentenbestand braucht, kommt mit nomic-embed-text oder all-minilm-l6-v2 auch auf dem Pi 5 weit – Embedding-Inference ist erheblich weniger rechenintensiv als Textgenerierung.
Ein praktischer Tipp aus der Community: Modelle nicht direkt vom Pi herunterladen, sondern vorab auf einem stärkeren Rechner prüfen und dann per rsync auf die NVMe-SSD des Pi übertragen. Das spart Zeit und vermeidet halbfertige Downloads bei instabiler Verbindung, die den Volume-Mount beim nächsten Container-Start zum Problem machen können.
Typische Stolperfallen im Betrieb – und wie man sie vermeidet
Wer den Stack zum ersten Mal aufsetzt, trifft auf eine Handvoll wiederkehrender Probleme, die sich in der Homelab-Community gut dokumentiert haben. Das erste ist der Swap-Konflikt: Ohne explizites Swap-Limit im Docker-Compose-File kann ein Inference-Container bei Speicherknappheit aggressiv in den Swap ausweichen, was die Latenz von zehn Sekunden auf mehrere Minuten hochtreibt und die SD-Karte – falls noch als Boot-Medium genutzt – beschleunigt verschleißt. Die Lösung: entweder ein dediziertes Swap-Limit im Compose-File setzen oder besser ganz auf eine NVMe-SSD als Systemlaufwerk umsteigen, das den Wear-Faktor deutlich reduziert.
Das zweite Problem ist die cgroup-Konfiguration. Auf manchen Pi-OS-Versionen sind cgroup v2 Memory-Controller nicht standardmäßig aktiviert, was dazu führt, dass Docker Container-Memory-Limits nicht korrekt durchsetzt. Die Lösung findet sich in der cmdline.txt: cgroup_memory=1 cgroup_enable=memory als Kernel-Parameter eintragen, dann neu starten. Ohne diese Einstellung laufen Container-Limits ins Leere.
Ein dritter Stolperstein betrifft den Modell-Ladevorgang: Große GGUF-Dateien brauchen beim ersten Start mehrere Minuten, bis sie vollständig in den RAM gemappt sind. Wer in dieser Phase bereits API-Anfragen schickt, bekommt Timeout-Fehler. Ollama und LocalAI bieten Health-Check-Endpunkte, die man im Compose-File als healthcheck hinterlegen sollte, damit Traefik den Upstream erst nach erfolgreichem Modell-Load als verfügbar markiert. Das ist kein Nischenproblem, sondern tritt bei jedem Container-Neustart auf.
Was bleibt – und was als Nächstes kommt
Der Raspberry Pi 5 als lokaler KI-Hub ist 2026 kein Bastelprojekt mehr für wenige Nerds. Die Container-Stacks reifen, die Tiny-Modelle werden besser, und das Thema Datensouveränität gewinnt im Smart-Home-Kontext an Gewicht. Edge Computing auf ARM-Hardware ist dabei nicht die Nische – es ist die Antwort auf eine konkrete Frage: Wie viele meiner Heimautomations-Daten will ich wirklich in eine Cloud schicken?
Was noch fehlt, sind stabilere, offiziell gepflegte ARM64-Container-Images direkt von den Inference-Engine-Projekten, bessere Modell-Kompatibilitätstabellen für Pi-Hardware und einfachere Onboarding-Stacks für Menschen ohne Docker-Erfahrung. Die Community arbeitet daran – das Tempo ist deutlich gestiegen.
Welches Modell läuft bei Ihnen auf dem Pi – oder was hält Sie noch davon ab, es auszuprobieren?



Was halten Sie von dem Thema? Hier können Sie mit anderen Leserinnen und Lesern ins Gespräch gehen.
Mitreden & diskutieren
Ihre Meinung zählt — teilen Sie Gedanken, Fragen oder Erfahrungen zu diesem Artikel.