
Kubernetes 1.36 ist seit Frühjahr 2026 die aktuelle stabile Version und bringt für Cluster-Admins mehr als nur ein Versions-Bump: Taints und Tolerations wandern von der reinen Node-Ebene auf die Geräte-Ebene, Preemption wird workload-bewusst, und der Scheduler bekommt handfeste Performance-Verbesserungen. Wer Multi-Tenancy-Cluster oder GPU-Pools betreibt, sollte sich die Details ansehen, bevor der nächste Upgrade-Slot im Wartungsfenster steht.
Kubernetes 1.36: Was für Cluster-Admins wirklich zaehlt
Jede neue Kubernetes-Version bringt eine lange Liste an Enhancements, von denen die meisten für den Alltagsbetrieb irrelevant sind. Bei Kubernetes 1.36 ist das anders: Der Release adressiert direkt Probleme, die Betreiber von gemischten Hardware-Clustern seit Jahren mit Workarounds lösen mussten. Statt generischer API-Kosmetik gibt es handfeste Scheduling-Kontrollen, die Multi-Tenancy-Isolation und Workload-Placement-Policies konkret verändern.
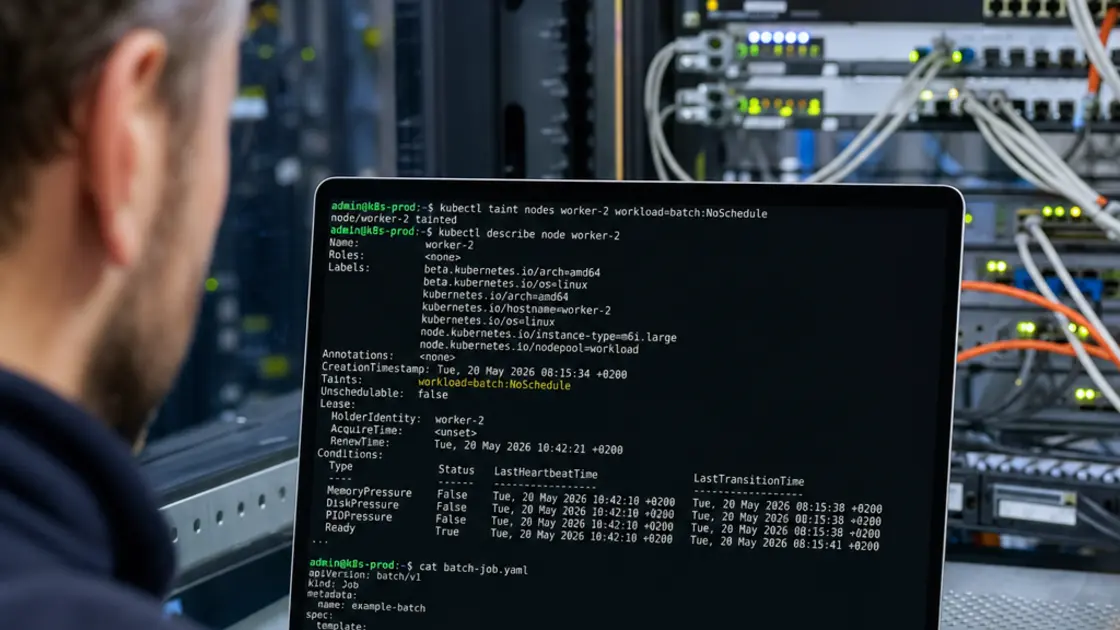
Im Zentrum steht die Weiterentwicklung von Taints und Tolerations. Das klassische Konzept – Nodes stoßen Pods ab, sofern keine passende Toleration vorliegt – existiert seit Jahren und ist stabil. Neu ist, dass dieses Prinzip jetzt auch auf einzelne Geräte innerhalb eines Nodes anwendbar ist. Für Cluster-Admins, die GPUs, SmartNICs oder andere spezialisierte Hardware verwalten, ist das ein Kontrollmechanismus, der bislang schlicht fehlte.
Persönlich finde ich diesen Schritt überfällig. Wer schon einmal versucht hat, in einem gemeinsam genutzten Cluster ein einzelnes defektes GPU-Device von der restlichen Kapazität eines Nodes zu isolieren, kennt die hässlichen Zwischenlösungen mit Labels, Node-Drains und manuellem Umschreiben von DaemonSets. Kubernetes 1.36 macht daraus eine native Funktion statt eines Bastel-Workarounds.
Die Zahlen hinter dem Release
Kubernetes 1.36 umfasst laut offiziellem Changelog rund 70 Enhancements. Davon graduieren 18 Features zu Stable, 25 erreichen Beta-Status, und weitere 25 sind neu als Alpha markiert. Diese Verteilung zeigt, wohin sich das Projekt bewegt: Ein deutlicher Schwerpunkt liegt auf Security-Hardening, auf AI- und ML-Workloads sowie auf API-Skalierbarkeit für große Cluster.
Für die Praxis heißt das: Nicht jedes neue Feature ist sofort produktionsreif. Alpha-Features benötigen weiterhin explizite Feature-Gates und sollten in produktiven Clustern mit Vorsicht behandelt werden. Beta-Features, die standardmäßig aktiviert sind, laufen dagegen automatisch mit dem Upgrade – das betrifft insbesondere die Dynamic-Resource-Allocation-Erweiterungen, auf die dieser Artikel gleich näher eingeht.
Die Kubernetes-eigenen Release Notes und der Changelog auf GitHub sind für Admins die verlässlichste Quelle, um zu prüfen, welches Feature in welchem Status ist – Blogposts und Drittanbieter-Analysen sind gute Einordnungshilfen, aber die API-Details ändern sich zwischen Beta-Iterationen mitunter noch.
Taints und Tolerations: Die Basismechanik bleibt, der Kontext waechst
Bevor es um die neuen Geräte-Taints geht, lohnt eine kurze Auffrischung der Grundlagen, weil sie in Diskussionen häufig verwechselt werden. Taints werden auf Nodes gesetzt und wirken abstoßend: Ein Pod ohne passende Toleration wird auf einem getainteten Node nicht geschedult. Der Befehl dafür ist unverändert simpel:
kubectl taint nodes node1 key=value:NoSchedule
Drei Effekte stehen zur Auswahl, und die Unterscheidung ist entscheidend für die Cluster-Governance: NoSchedule verhindert neues Scheduling, PreferNoSchedule ist eine weiche Präferenz, die der Scheduler nach Möglichkeit respektiert, und NoExecute entfernt sogar bereits laufende Pods vom Node. Wer diese drei Effekte verwechselt, produziert entweder unschedulbare Workloads oder ungewollte Evictions – ein klassischer Anfängerfehler, der auch erfahrenen Admins gelegentlich passiert, wenn ein Taint-Skript kopiert und nicht angepasst wird.
Wichtig bleibt außerdem die Abgrenzung zu Node-Affinity und Labels: Labels und Node-Selectors steuern Anziehung, Taints und Tolerations steuern Abstoßung. Beide Mechanismen greifen an unterschiedlichen Stellen im Scheduling-Algorithmus und lassen sich kombinieren – aber genau diese Kombination aus Taints, Node-Affinity und Pod Topology Spread Constraints führt in der Praxis oft zu Pods, die dauerhaft im Pending-Status hängen, weil die Bedingungen sich gegenseitig ausschließen. Die offizielle Kubernetes-Dokumentation zu Taints and Tolerations bleibt hier die verlässlichste Referenz, gerade weil sich die Feinheiten der Effekte in Detailfragen leicht falsch interpretieren lassen.
DRA Device Taints: Wenn Hardware selbst tainted wird
Das eigentliche Kernstück des Releases für Cluster-Scheduling ist die Weiterentwicklung der Dynamic Resource Allocation, kurz DRA. Bereits in aktuelle Kubernetes-Versionen wurden Device-Taints und -Tolerations für physische Geräte als Alpha-Feature eingeführt. Mit Kubernetes 1.36 graduieren sie zu Beta und sind standardmäßig aktiviert – ohne dass ein separates Feature-Gate gesetzt werden muss.
Konkret bedeutet das: Ein DRA-Treiber kann einzelne Geräte, etwa eine bestimmte GPU in einem Node mit mehreren Beschleunigern, als „tainted“ markieren. Nur Pods mit einer expliziten Toleration für diesen Geräte-Taint dürfen das entsprechende Device nutzen. Cluster-Admins definieren dafür eine sogenannte DeviceTaintRule, mit der sich beispielsweise alle von einem bestimmten Treiber verwalteten Geräte gebündelt tainten lassen.
Der praktische Nutzen zeigt sich in zwei Szenarien, die für Betreiber von Self-Hosting-Clustern mit gemischter Hardware alltäglich sind. Erstens: feinere Kontrolle darüber, welche Teams oder Namespaces auf welche Hardware-Pools zugreifen dürfen – Premium-GPUs lassen sich so gezielt für bestimmte Workloads reservieren, ohne den gesamten Node zu blockieren. Zweitens: automatisches Rescheduling weg von fehlerhaften oder instabilen Geräten, ohne dass der komplette Node aus dem Scheduling-Pool genommen werden muss. Das ist ein klarer Unterschied zur bisherigen Praxis, bei der ein defektes Device meist den ganzen Node lahmlegte, weil es keine Möglichkeit gab, unterhalb der Node-Ebene zu differenzieren.
Der Kubernetes-Blog-Beitrag zum Sneak Peek von 1.36 beschreibt die DeviceTaintRule im Detail – Admins, die produktiv mit GPU-Treibern arbeiten, sollten diese Doku parallel zur treiberspezifischen Dokumentation lesen, weil sich Beta-APIs zwischen Iterationen noch verschieben können.
Partitionable Devices und Consumable Capacity
Neben den Device-Taints bringt Kubernetes 1.36 zwei weitere DRA-Erweiterungen mit, die ebenfalls Beta-Status erreichen und standardmäßig aktiv sind: Partitionable Devices und Consumable Capacity. Beide Features hängen eng mit dem Taint-Mechanismus zusammen, weil sie die Granularität erhöhen, mit der der Scheduler über Hardware entscheidet.
Partitionable Devices erlauben es, ein physisches Gerät zur Laufzeit in Partitionen aufzuteilen, deren Größe der Scheduler dynamisch anfordert. Consumable Capacity ermöglicht dem Scheduler, Kapazität eines Geräts feingranular zu konsumieren, statt ein Device immer als monolithische Einheit zu behandeln. In Kombination mit Device-Taints entsteht damit ein Werkzeugkasten, mit dem sich Hardware-Pools in Cluster-Umgebungen deutlich präziser segmentieren lassen als bisher.
Für Cluster-Scheduling in AI-lastigen Umgebungen ist das relevant, weil GPU-Ressourcen selten homogen genutzt werden: Ein Trainingsjob braucht eine ganze Karte, ein Inferenz-Workload oft nur einen Bruchteil davon. Vorher musste man dafür entweder auf externe Scheduler-Erweiterungen zurückgreifen oder Ressourcen grobkörnig zuweisen und Kapazität verschwenden. Mit den neuen Beta-Features lässt sich das nativer im Cluster abbilden – ein Schritt, der Kubernetes für gemischte AI-Workloads praxistauglicher macht, ohne dass man auf proprietäre Scheduler-Add-ons ausweichen muss.
Workload-Aware Preemption: Alpha mit Sprengkraft
Während die DRA-Erweiterungen bereits Beta sind, bleibt Workload-Aware Preemption in Kubernetes 1.36 klar im Alpha-Status und muss über ein Feature-Gate explizit aktiviert werden. Wer die Funktion in produktiven Multi-Tenancy-Clustern einsetzen will, sollte sich der damit verbundenen Instabilität bewusst sein und das Feature zunächst in einer Staging-Umgebung testen.
Die Grundidee ist trotzdem bemerkenswert: Bisherige Preemption-Logik im Cluster-Scheduling behandelt jeden Pod isoliert. Bei zusammengehörigen Workloads – etwa verteilten Trainingsjobs, die aus mehreren Pods bestehen – führte das dazu, dass einzelne Pods eines Jobs verdrängt wurden, während der Rest weiterlief und damit blockiert war, ohne echten Fortschritt zu machen. Workload-Aware Preemption betrachtet zusammengehörige Pod-Gruppen als eine Entity und trifft Preemption-Entscheidungen entsprechend ganzheitlicher – ein Ansatz, der besonders für verteilte AI-Trainingsjobs Fragmentierung vermeiden soll.
Wie sich das konkret auf bestehende PriorityClasses auswirkt, ist noch nicht vollständig in der Stable-Dokumentation ausformuliert; die Antwort aus den bisherigen Community-Diskussionen lautet, dass Priorities weiterhin relevant bleiben, die Preemption-Logik aber zusätzlich die Zugehörigkeit von Pods zu einer Gruppe berücksichtigt. Cluster-Admins mit AI-Workloads sollten das Feature im Blick behalten, aber nicht überstürzt in produktive Setups übernehmen – Alpha bedeutet Alpha, auch wenn die Idee überzeugend klingt.
Scheduler-Performance und PreBind-Parallelisierung
Neben den großen, sichtbaren Features gibt es in Kubernetes 1.36 eine eher unauffällige, aber für große Cluster spürbare Verbesserung: PreBind-Plugins können jetzt parallel ausgeführt werden, sofern sie über die Option AllowParallel: true explizit dafür markiert sind. Das reduziert die Bind-Latenz, also die Zeit zwischen Scheduling-Entscheidung und tatsächlichem Pod-Start.
In Clustern mit wenigen hundert Nodes fällt dieser Effekt kaum auf. Wer aber Tausende von Pods pro Minute schedult – etwa in Batch-Verarbeitung oder bei kurzlebigen CI/CD-Workloads – wird die kumulierte Zeitersparnis bemerken. Zusätzlich gibt es Optimierungen im Client-go-Stack und in den Informer-Mechanismen, die für konsistentere Store-Updates vor Events sorgen und damit die Stabilität von Controllern und dem Scheduler selbst verbessern.
Diese Änderungen sind kein Marketing-Feature, das man auf einer Release-Folie präsentiert, aber genau solche Details entscheiden am Ende darüber, ob ein Cluster unter Last stabil bleibt oder ob der Scheduler zum Flaschenhals wird. Wer produktiv mit vielen kurzlebigen Workloads arbeitet, sollte diese Verbesserung in Benchmark-Tests nach dem Upgrade konkret nachmessen.
Multi-Tenancy und Governance in Self-Hosting-Clustern
Für Betreiber von Self-Hosting-Clustern mit mehreren Teams oder Kunden auf derselben Infrastruktur sind die neuen Taint-Mechaniken vor allem ein Governance-Werkzeug. Namespace-Isolation allein regelt, wer welche Ressourcen im Cluster sieht und ansprechen darf – sie regelt aber nicht, welche physische Hardware ein Workload tatsächlich zugewiesen bekommt. Genau diese Lücke schließen Device-Taints in Kombination mit Tolerations auf Pod-Ebene.
Ergänzend spielt hier auch die Weiterentwicklung von CEL-basierten Mutating Admission Policies eine Rolle, die in Kubernetes 1.36 weiter ausgebaut wurden. Sie erlauben es, Regeln zu definieren, welche Kombinationen aus Taints, Tolerations und Labels für bestimmte Namespaces überhaupt zulässig sind – ohne dass dafür zwingend ein externer Admission-Webhook betrieben werden muss. Das reduziert externe Abhängigkeiten, ersetzt aber nicht jede komplexe Webhook-Pipeline vollständig; wer aufwendige Integrationslogik benötigt, wird weiterhin auf externe Systeme zurückgreifen.
Für die tägliche Cluster-Governance bedeutet das: Ein Admin kann künftig per Policy verhindern, dass ein Team versehentlich eine Toleration für Premium-GPU-Taints in seinen Deployment-Manifesten hinterlegt, obwohl es dafür weder Budget noch Berechtigung hat. Das ist kein Sicherheitsfeature im klassischen Sinne, aber ein handfestes Werkzeug gegen Ressourcen-Wildwuchs in Multi-Tenancy-Umgebungen – und genau solche Wildwuchs-Probleme sind es, die in gewachsenen Clustern am Ende die meiste Admin-Zeit fressen.
Upgrade-Pfad: Von aelteren Kubernetes-Versionen auf 1.36
Wer noch auf einer deutlich älteren Kubernetes-Version unterwegs ist, sollte den Umstieg auf 1.36 nicht als einzelnen großen Sprung planen, sondern über die üblichen Zwischenversionen gehen – das entspricht der von Kubernetes empfohlenen Praxis, Upgrades schrittweise über aufeinanderfolgende Minor-Versionen durchzuführen. Ein direkter Sprung über mehrere Minor-Versionen hinweg ist offiziell nicht unterstützt und erhöht das Risiko unerwarteter API-Inkompatibilitäten erheblich.
Vor dem eigentlichen Upgrade lohnt sich eine Bestandsaufnahme der bestehenden Taint- und Toleration-Konfigurationen: Welche Nodes tragen welche Taints, und welche Pods verlassen sich auf welche Tolerations? Diese Inventur ist Pflicht, weil die neuen Device-Taints als Beta-Feature standardmäßig aktiv werden und in Clustern mit DRA-Treibern unmittelbar wirksam werden können – ohne dass ein Admin dafür aktiv etwas geändert haben muss.
Konkrete Schritte für den Umstieg: Zunächst ein Staging-Cluster auf 1.36 heben und die vorhandenen Workloads dort laufen lassen, insbesondere jene mit GPU- oder DRA-Bezug. Anschließend die Kubelet-Authorization-Einstellungen und die neuen Security-Defaults prüfen, da Kubernetes 1.36 hier verschärfte Vorgaben mitbringt. Erst danach den produktiven Cluster im gewohnten Wartungsfenster aktualisieren, mit Rollback-Plan für den Fall, dass eine Beta-Funktion unerwartet mit bestehenden Admission-Policies kollidiert. Der Release-Bericht von InfoQ zu Kubernetes 1.36 gibt einen kompakten Überblick über die sicherheitsrelevanten Änderungen, die bei diesem Check besonders relevant sind.
Wichtig ist außerdem: DRA-Treiber für spezifische Hardware, etwa für bestimmte GPU-Modelle, folgen ihrem eigenen Release-Zyklus. Ein Upgrade des Kubernetes-Kerns garantiert nicht automatisch, dass der eingesetzte Treiber die neuen Device-Taint-Funktionen bereits vollständig unterstützt. Hier hilft nur der Blick in die Treiber-Dokumentation des jeweiligen Hardware-Anbieters, bevor man sich auf die neuen Funktionen in der Produktion verlässt.
Was bleibt fuer den Cluster-Alltag?
Kubernetes 1.36 ist kein Release, der den Alltag von Cluster-Admins über Nacht verändert. Die klassischen Taints und Tolerations funktionieren wie gewohnt, kubectl-Befehle bleiben gleich, und die grundsätzliche Scheduling-Logik ist stabil. Was sich ändert, ist die Feinheit der Kontrolle: Hardware wird zum eigenständigen Objekt im Scheduling-Prozess, nicht mehr nur eine Eigenschaft des Nodes.
Ob sich der Aufwand lohnt, hängt stark vom eigenen Cluster-Profil ab. Wer ausschließlich stateless Webservices auf homogener Hardware betreibt, wird die neuen DRA-Features kaum vermissen. Wer dagegen GPUs, SmartNICs oder andere Spezialhardware in einem geteilten Cluster verwaltet, bekommt mit Kubernetes 1.36 endlich Werkzeuge, die bisher nur über Umwege oder Drittanbieter-Lösungen verfügbar waren. Ist das schon die endgültige Lösung für Hardware-Governance in Kubernetes? Eher ein solider Zwischenschritt – Workload-Aware Preemption zeigt, wohin die Richtung weitergeht, ist aber noch zu unfertig für den produktiven Einsatz.


Was halten Sie von dem Thema? Hier können Sie mit anderen Leserinnen und Lesern ins Gespräch gehen.
Mitreden & diskutieren
Ihre Meinung zählt — teilen Sie Gedanken, Fragen oder Erfahrungen zu diesem Artikel.