
Moment mal. Ich hab letzte Woche noch einem KI-App-Chatbot mein Bewerbungsschreiben zum Überarbeiten geschickt. Und dann das: Sicherheitsforscher decken auf, dass Millionen Chats, Bilder und hochgeladene Dokumente aus populären KI-Apps offen im Netz lagen – nicht weil die KI selbst „undicht“ war, sondern weil die dahinterliegenden APIs und Cloud-Verbindungen so schlampig abgesichert waren wie ein Fahrradschloss aus dem Discounter.
Was tatsächlich passiert ist – und warum „KI-Leck“ oft die falsche Überschrift ist
Krass, aber wichtig: Die meisten dieser Sicherheitslücken haben technisch gar nichts mit der künstlichen Intelligenz zu tun. Die KI-Modelle selbst – also ChatGPT, Gemini, Claude und Co. – lecken keine Daten. Das Problem sitzt eine Ebene tiefer. Es geht um die Apps, die diese Modelle nutzen, und um die Art, wie deren Entwickler API-Schlüssel, Cloud-Speicher und Nutzerauthentifizierung eingebaut haben. Oder eben nicht eingebaut haben.
Eine Analyse zu Android-KI-Apps berichtet von laut Bericht rund 730 Terabyte exponierter Nutzerdaten – eine Zahl, die ohne Zugang zur Originalstudie nicht unabhängig verifiziert werden kann, die aber die Größenordnung des Problems illustriert. Was dagegen methodisch belastbar ist: 72 Prozent der untersuchten Android-KI-Apps enthielten mindestens ein hartcodiertes Secret. Im Schnitt lagen 5,1 sensible Datenelemente pro App offen. Das ist kein Einzelfall. Das ist ein Muster.
Der Ablauf ist immer ähnlich. Eine Entwicklerin baut schnell eine neue KI-App. Sie integriert eine externe API – für Spracherkennung, Texterzeugung, Bildsynthese. Den API-Key schreibt sie direkt in den App-Code. Fertig. Die App geht in den Store. Und der Key steckt jetzt in Millionen installierten Apps, auslesbar für jeden mit den richtigen Tools. So einfach. So gefährlich.
Hartcodierte Secrets: Der Klassiker, der nie aufhört
Was bedeutet „hartcodiertes Secret“ eigentlich konkret? Stellen Sie sich vor, Sie schreiben Ihr WLAN-Passwort auf einen Zettel und kleben ihn außen ans Fenster. Ungefähr so sieht es aus, wenn ein API-Key direkt im Quellcode einer App steckt. Wer die App-Datei entpackt – was technisch nicht schwer ist –, sieht den Key im Klartext.
Mit diesem Key kann ein Angreifer die API des KI-Dienstes direkt ansprechen. Auf Kosten des App-Betreibers. Oder schlimmer: Er kann auf Backend-Endpunkte zugreifen, die eigentlich nur für die App gedacht sind. Endpunkte, hinter denen Chat-Historien, hochgeladene Bilder, Sprachaufnahmen oder Dokumente liegen. Die KI-App-Sicherheit bricht also nicht an der KI, sondern am Secret-Management zusammen.
Laut dem API-Sicherheitsbericht 2025 von Traceable bestehen API-Sicherheitsverletzungen weiterhin – und generative KI erhöht die Risiken, weil deutlich mehr Apps deutlich mehr externe Dienste anbinden. Jede neue Anbindung ist eine potenzielle neue Angriffsfläche. Das ist meine persönliche Einschätzung, aber die Zahlen sprechen eine klare Sprache.
Besonders alarmierend ist dabei die Kombination aus Geschwindigkeit und Sorglosigkeit. Viele der betroffenen Apps entstanden im Zuge des KI-Booms der letzten zwei Jahre, bei dem Entwickler im Wochentakt neue Assistenten, Bild-Generatoren und Dokumentenhelfer auf den Markt warfen. Das Muster ist dabei so verbreitet, dass die Sicherheitsprobleme rund um schnell generierte KI-Apps inzwischen ein eigenständiges Forschungsfeld geworden sind. Wer unter Zeitdruck deployed, lässt Security-Reviews systematisch weg – mit vorhersehbaren Folgen.
Cloud-Buckets, offene Endpunkte und kaputte Auth-Flows
Hartcodierte Keys sind nur eine Fehlerklasse. Daneben gibt es drei weitere, die Sicherheitsforscher immer wieder finden.
Offene Cloud-Buckets. KI-Apps speichern Nutzerdaten irgendwo. Meist in Cloud-Storage wie AWS S3, Google Cloud Storage oder Azure Blob. Wenn dieser Bucket ohne Zugriffsschutz konfiguriert ist – was erschreckend oft vorkommt –, kann jeder mit der richtigen URL die Dateien abrufen. Keine Authentifizierung nötig. Keine Kenntnis des API-Keys. Einfach die URL raten oder mit einem Crawler suchen. Die Datenleck-Fälle, über die BleepingComputer und The Hacker News regelmäßig berichten, folgen diesem Schema auffällig häufig.
Fehlende oder kaputte Authentifizierung in Mobile-Apps. Viele KI-Apps nutzen OAuth-Flows für die Nutzeranmeldung oder für den Zugriff auf Cloud-Ressourcen. Die Android Developers Dokumentation listet explizit, welche API-Fehler dabei typischerweise auftreten: fehlende `redirect_uri`-Absicherung, fehlender CSRF-Schutz, fehlerhafte Token-Validierung. Wer einen solchen Fehler in einer populären KI-App findet, kann sich unter Umständen als andere Person ausgeben – und deren Chat-Verlauf abrufen.
Zu weit offene API-Endpunkte. Eine API sollte nur das zurückgeben, was der anfragende Nutzer auch wirklich sehen darf. In der Praxis legen viele Apps Endpunkte offen, die alle Nutzerchats einer App liefern, wenn man den richtigen Parameter kennt. Das nennt sich Broken Object Level Authorization, kurz BOLA, und ist seit Jahren auf der OWASP-Top-10-Liste für API-Sicherheit. Bei KI-Apps ist das Problem besonders heikel, weil in den Chats oft sehr persönliche Informationen stecken.
Was wirklich in Ihren Chats steckt – und warum das so brisant ist
Okay, jetzt wird es persönlich. Denken Sie kurz an Ihre letzten zehn Konversationen mit einer KI-App. Haben Sie dort Dokumente hochgeladen? Adressen eingegeben? Medizinische Fragen gestellt? Firmendaten eingefügt, um einen Text zusammenfassen zu lassen? Genau das ist das Material, das bei einem Datenleck offen liegt.
Das eigentliche Risiko ist laut Experten nicht nur der Chattext selbst. Es sind die Metadaten, die hochgeladenen Dateien, die verknüpften Cloud-Zugänge und die Session-Tokens. Wer einen gültigen Token abgreift, kann sich als eingeloggter Nutzer verhalten – und hat damit potenziell Zugriff auf alles, was dieser Nutzer in der App gespeichert hat. Für Privatpersonen ist das unangenehm. Für Unternehmen, die KI-Apps intern einsetzen, kann es existenzbedrohend sein. Das Thema Schatten-KI – also KI-Apps, die Mitarbeitende ohne Wissen der IT-Abteilung nutzen – verstärkt dieses Risiko erheblich.
Vibe-Coding-Projekte und schnell zusammengebaute KI-Tools machen das Problem noch größer. Wer in wenigen Stunden eine App auf Basis von Sprachmodellen baut und direkt deployed, denkt selten an Secret-Scanning, API-Rate-Limits oder Bucket-Policies. Das Ergebnis: Tausende kleiner KI-Apps mit denselben strukturellen Fehlern, die professionelle Entwicklerteams eigentlich längst kennen – und vermeiden.
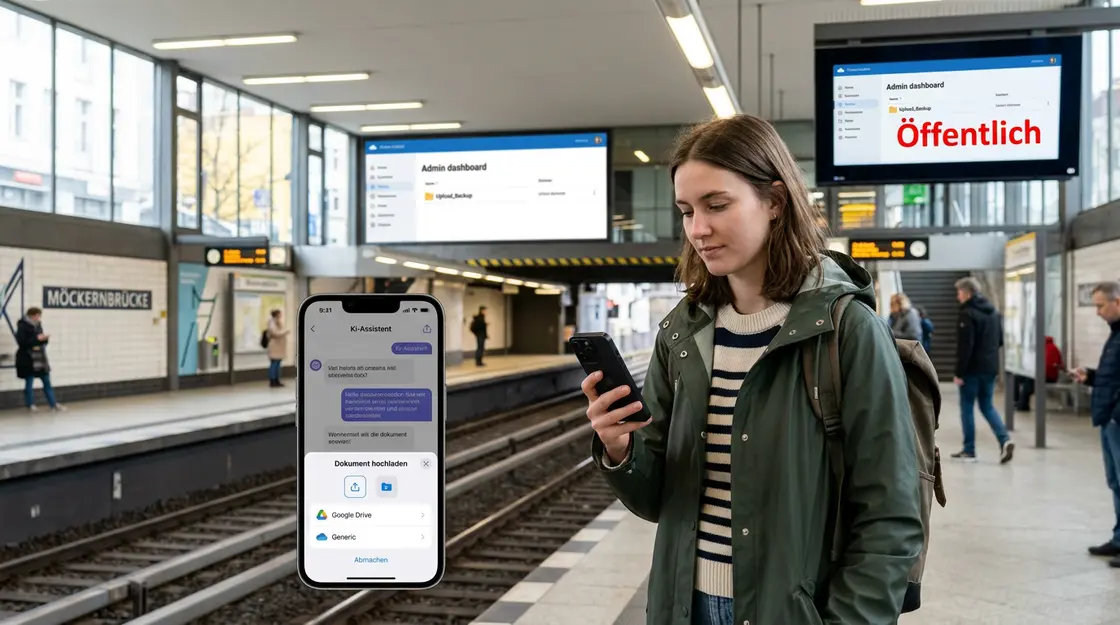
Welche Apps sind betroffen – und wie erkennen Sie unsichere KI-Apps?
Konkrete App-Namen ohne offizielle Bestätigung durch die Entwickler zu nennen, wäre journalistisch unsauber. Was sich aber sagen lässt: Die Risikogruppe ist klar umrissen. Es sind vor allem kleine bis mittelgroße KI-Apps im Consumer-Bereich – Bild-Generatoren, KI-Schreibassistenten, Chat-Apps auf Basis von OpenAI oder Gemini, Stimmen-Kloner, Zusammenfassungs-Tools. Die großen Plattformen wie ChatGPT direkt, Gemini oder Claude haben eigene Sicherheitsteams und Audit-Prozesse. Das schließt Fehler nicht aus, aber es ist ein anderes Risikoniveau als bei einer App, die drei Entwickler in drei Wochen gebaut haben.
Wie erkennen Sie, ob eine KI-App unsicher ist? Hundertprozentig von außen nicht. Aber es gibt Warnsignale. Eine App, die keine Datenschutzerklärung hat oder eine, die aus dem letzten Jahr stammt und seitdem nie aktualisiert wurde, ist ein rotes Flag. Eine App, die um Zugriff auf Kontakte, Kamera oder Dateisystem bittet, obwohl das für ihre Funktion nicht nötig ist, ist ein weiteres. Und eine App mit wenigen Downloads, keinen Reviews und unklarem Entwicklerhintergrund sollte grundsätzlich mit erhöhter Vorsicht behandelt werden.
Konkrete Checkliste: Was Sie jetzt tun können
- Sensible Dokumente nicht hochladen. Lebenslauf, Ausweiskopie, Firmenunterlagen, Krankenakten – diese Dateien haben in einer unbekannten KI-App nichts zu suchen. Punkt.
- App-Berechtigungen prüfen. Android und iOS zeigen, welche Berechtigungen eine App nutzt. KI-Schreibassistent braucht keinen Standort. Stutzig werden.
- Apps regelmäßig aktualisieren. Sicherheitspatches kommen über Updates. Wer Auto-Update deaktiviert hat, bleibt auf alten, bekannten Lücken sitzen.
- Wenig genutzte Apps löschen. Jede installierte App ist eine potenzielle Angriffsfläche. Was Sie nicht brauchen, fliegt raus.
- Kein Passwort-Recycling bei KI-App-Accounts. Wenn eine App gehackt wird und Sie dasselbe Passwort auf zehn anderen Diensten nutzen, haben Sie ein viel größeres Problem.
- Bekannte Plattformen bevorzugen. Für sensible Nutzung lieber direkt zu ChatGPT, Claude oder Gemini – mit eigenen Accounts und klaren Datenschutzeinstellungen – als zu Drittanbieter-Apps, die dieselben Modelle im Hintergrund nutzen.
Was Entwickler jetzt ändern müssen – und warum der Druck auf die Branche steigt
Aus technischer Sicht ist die Lösung bekannt. Secret-Scanning in CI/CD-Pipelines – also automatische Prüfung, ob versehentlich API-Keys im Code landen – ist mit Tools wie GitHub’s Secret Scanning oder GitLeaks einfach einzurichten. Environment Variables statt hartcodierter Keys sind Standard. Bucket-Policies mit Least-Privilege-Prinzip – also: jeder Dienst bekommt nur genau die Rechte, die er wirklich braucht – sind keine Raketenwissenschaft.
Das eigentliche Problem ist der Produktionsdruck. KI-Apps entstehen gerade in einem Tempo, das Sicherheitsreviews strukturell ausblendet. Wer in drei Tagen von Idee bis App-Store-Veröffentlichung kommt, macht keinen Penetration-Test. Wer mit No-Code-Plattformen und KI-generiertem Code baut, verlässt sich darauf, dass die Plattform schon sicher ist. Oft ist sie es nicht – oder die Konfiguration des Nutzers macht sie unsicher.
KI-App-Sicherheit ist damit kein exotisches Nischenthema mehr. Es ist die dringende Hausaufgabe einer ganzen Branche. Und solange die Hausaufgaben nicht gemacht werden, zahlen Nutzerinnen und Nutzer den Preis – mit ihren privatesten Daten.
Gegenargument: Sind die Risiken nicht übertrieben?
Ein Einwand, den man hören wird: Die meisten Nutzerinnen und Nutzer sind doch keine interessanten Angriffsziele. Warum sollte jemand ausgerechnet meinen Chat-Verlauf mit einem KI-Schreibassistenten abgreifen wollen? Das klingt nach einem vernünftigen Argument. Es greift aber aus zwei Gründen zu kurz.
Erstens sind moderne Angriffe selten gezielt auf Einzelpersonen. Wer einen offenen Cloud-Bucket findet, lädt nicht gezielt Ihre Dateien herunter – er lädt alles herunter, was im Bucket liegt. Automatisiert, in Minuten. Die Daten werden anschließend sortiert, indexiert und teils weiterverkauft. Ob Sie „interessant“ sind, entscheidet ein Algorithmus, nicht ein Mensch. Zweitens unterschätzen die meisten Menschen, wie viele sensible Informationen sie tatsächlich in KI-Apps eingeben. Eine einzige Konversation, in der Sie Arbeitgebernamen, Wohnort und Gesundheitsproblem erwähnen, kann für Phishing-Angriffe oder Identitätsmissbrauch ausreichend sein. Die Kombination von Daten ist das eigentliche Risiko – nicht der einzelne Datenpunkt.
API-Sicherheit: Das eigentliche Schlachtfeld
Ich finde es bemerkenswert, wie lange dieser Zusammenhang in der öffentlichen Debatte unter dem Radar geblieben ist. Jedes Mal, wenn ein KI-Dienst in die Schlagzeilen gerät, dreht sich die Diskussion um das Modell, um Training, um Bias, um Copyright. Die eigentliche Sicherheitsfrage – wie ist die API dieser App abgesichert? – stellt kaum jemand öffentlich.
Dabei ist API-Sicherheit das zentrale Schlachtfeld. Generative KI hat die Zahl der Apps, die externe APIs anbinden, in kurzer Zeit vervielfacht. Jede dieser Anbindungen muss korrekt authentifiziert, auf Rate-Limits begrenzt, auf Input-Injection geprüft und im Monitoring überwacht werden. Das ist viel Arbeit. Es ist Arbeit, die sich nicht in einem Feature-Screenshot auf der App-Store-Seite zeigt. Und es ist Arbeit, die gerade systematisch vernachlässigt wird.
Bot-Angriffe machen das Problem akuter. Wer einen offenen API-Endpunkt findet, schickt nicht eine Anfrage, sondern tausende. Automatisiert. In Sekunden. Bis der Bucket leer ist oder das Rate-Limit greift – falls es eines gibt. Oft gibt es keines.
Was Regulierung leisten kann – und wo sie an Grenzen stößt
Auf politischer Ebene gibt es inzwischen erste Reaktionen. Der europäische AI Act adressiert bestimmte Hochrisiko-Systeme mit Transparenz- und Sicherheitsanforderungen. Die DSGVO verpflichtet Unternehmen, personenbezogene Daten angemessen zu schützen – theoretisch auch in KI-Apps. Praktisch fehlen vielen App-Store-Betreibern noch die Werkzeuge und die Kapazitäten, um KI-Apps systematisch auf Sicherheitslücken zu prüfen, bevor sie veröffentlicht werden.
Ein realistisches Szenario für die nächsten Jahre: App-Stores könnten verpflichtet werden, grundlegende Sicherheitsnachweise einzufordern, bevor eine KI-App zur Veröffentlichung zugelassen wird – ähnlich wie es in der Medizinproduktezulassung oder bei Finanz-Apps bereits ansatzweise existiert. Bis dahin bleibt die Verantwortung vor allem dort, wo sie strukturell am wenigsten hingehört: bei den Endnutzern, die selbst einschätzen sollen, welcher App sie vertrauen können.
Was bleibt – und was Sie sich jetzt fragen sollten
KI-App-Sicherheit ist kein abstraktes IT-Problem. Es ist die Frage, ob Ihre nächste Arztfrage, Ihr nächstes Bewerbungsschreiben oder Ihr nächstes Firmen-Brainstorming morgen irgendwo in einem offenen Cloud-Bucket liegt.
Die Lücken sind bekannt. Die Lösungen sind bekannt. Was fehlt, ist konsequente Umsetzung – von Entwicklern, von App-Store-Betreibern und, ja, auch von uns als Nutzerinnen und Nutzern, die KI-Apps oft unreflektiert mit sensiblen Daten füttern. Datenleck-Risiken bei KI-Apps werden nicht kleiner, solange der Markt für schnell gebaute Assistenten-Apps weiter explodiert.
Die eine Frage zum Schluss: Was haben Sie in den letzten vier Wochen in eine KI-App eingegeben – und wissen Sie wirklich, wo diese Daten gerade liegen?


Was halten Sie von dem Thema? Hier können Sie mit anderen Leserinnen und Lesern ins Gespräch gehen.
Mitreden & diskutieren
Ihre Meinung zählt — teilen Sie Gedanken, Fragen oder Erfahrungen zu diesem Artikel.