Die Zukunft der personalisierten Produktempfehlungen liegt in Graphdatenbanken: Während herkömmliche Datenbanken bei komplexen Kundenbeziehungen an ihre Grenzen stoßen, ermöglichen Graphdatenbanken Echtzeit-Empfehlungen mit bis zu 1.000-facher Performance-Steigerung. Doch welche Vor- und Nachteile bringen diese innovativen Datenstrukturen mit sich?
Online-Händler stehen heute vor einer enormen Herausforderung: Aus Millionen von Produkten und Nutzerdaten müssen sie in Millisekunden die perfekte Empfehlung für jeden einzelnen Kunden generieren. Herkömmliche relationale Datenbanken erreichen hier schnell ihre Leistungsgrenzen, während Graphdatenbanken eine völlig neue Dimension der Datenverarbeitung eröffnen.
Graphdatenbanken speichern und verarbeiten Informationen nicht in starren Tabellenstrukturen, sondern als miteinander verknüpfte Knoten und Kanten. Diese flexible Datenstruktur macht es möglich, komplexe Beziehungen zwischen Kunden, Produkten, Kategorien und Verhaltensmuster in Echtzeit zu analysieren – eine Eigenschaft, die sie zur idealen Lösung für moderne E-Commerce-Empfehlungssysteme macht.
Was sind Graphdatenbanken und wie funktionieren sie?
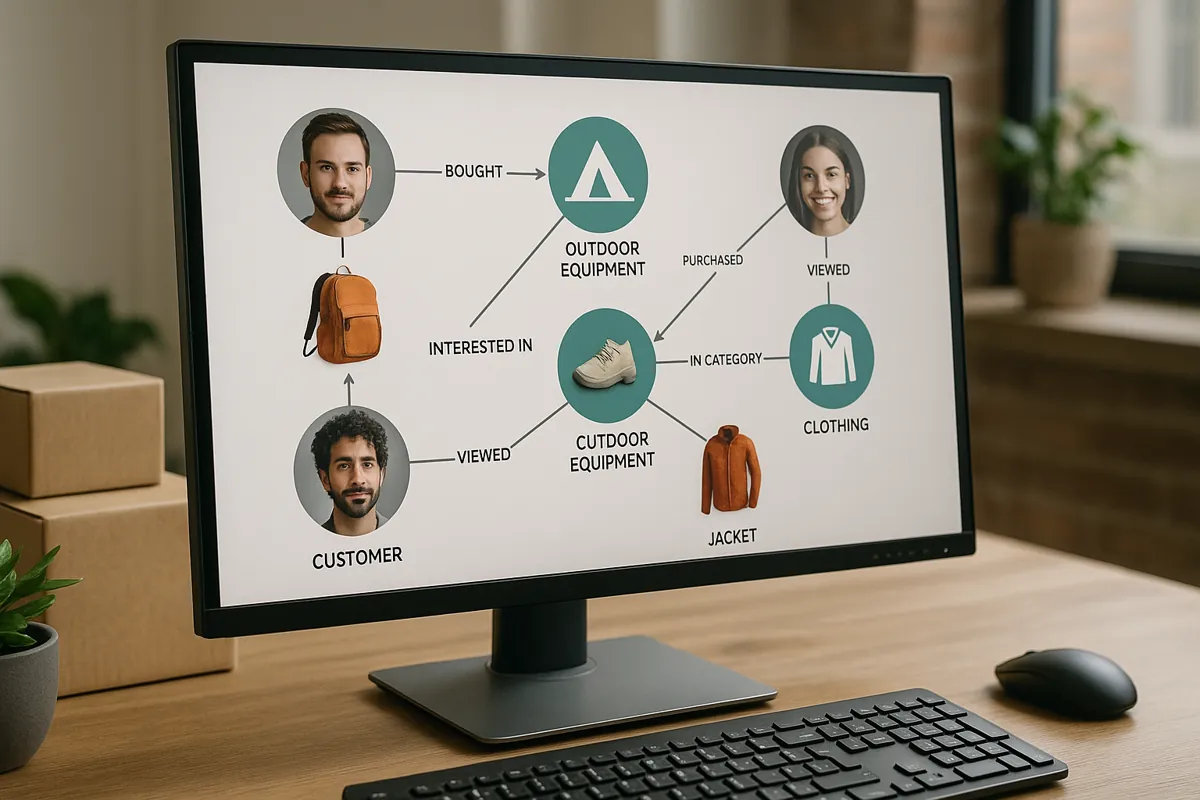
Eine Graphdatenbank basiert auf der mathematischen Graphentheorie und besteht aus drei Grundelementen: Knoten (Nodes), Kanten (Edges) und Eigenschaften (Properties). Während ein Knoten eine Entität wie einen Kunden oder ein Produkt repräsentiert, stellen Kanten die Beziehungen zwischen diesen Entitäten dar – beispielsweise „gekauft“, „bewertet“ oder „interessiert sich für“.
Im E-Commerce-Kontext könnte ein Graph so aussehen: Der Knoten „Kunde A“ ist über die Kante „hat gekauft“ mit dem Knoten „Produkt X“ verbunden. Gleichzeitig ist „Produkt X“ über „gehört zur Kategorie“ mit „Outdoor-Ausrüstung“ verknüpft. Diese natürliche Darstellung von Beziehungen macht Graphdatenbanken besonders effizient für die Analyse vernetzter Daten.
Der entscheidende Unterschied zu relationalen Datenbanken liegt in der Traversierung: Anstatt aufwendige JOIN-Operationen durchzuführen, „wandert“ die Abfrage einfach entlang der bereits bestehenden Verbindungen von Knoten zu Knoten. Dies ermöglicht deutlich schnellere Abfragen, insbesondere bei tief verschachtelten Beziehungen.
Vorteile von Graphdatenbanken im E-Commerce
Die Stärken von Graphdatenbanken kommen besonders im E-Commerce-Umfeld zur Geltung:
Echtzeitfähige Performance
Graphdatenbanken können je nach Anwendungsfall bis zu 1.000-mal schneller arbeiten als relationale Datenbanken. Dies ermöglicht Produktempfehlungen in Millisekunden, selbst bei Millionen von Datenpunkten.
Intuitive Datenmodellierung
Die Struktur einer Graphdatenbank entspricht der natürlichen Denkweise über Kundenbeziehungen. Marketing-Teams können ohne tiefe technische Kenntnisse nachvollziehen, wie Empfehlungen zustande kommen.
Flexible Skalierbarkeit
Neue Beziehungstypen und Datenquellen lassen sich problemlos in bestehende Graphstrukturen integrieren. Social-Media-Daten, IoT-Sensoren oder externe APIs können nahtlos eingebunden werden.
Erweiterte Analysemöglichkeiten
Graphdatenbanken ermöglichen komplexe Analysen wie Community-Detection, Influencer-Identification oder Betrugsaufdeckung durch Mustererkennung in Netzwerkstrukturen.
Nachteile und Herausforderungen von Graphdatenbanken
Trotz ihrer Vorteile bringen Graphdatenbanken auch Herausforderungen mit sich:
Komplexe Implementierung
Die Migration von relationalen Datenstrukturen zu Graphmodellen erfordert oft eine komplette Neukonzeption der Datenarchitektur. Dies kann zeitaufwendig und kostspielig sein.
Spezialisiertes Know-how erforderlich
Die Abfragesprachen wie Cypher (Neo4j) oder Gremlin unterscheiden sich deutlich von SQL. Entwicklerteams müssen entsprechend geschult werden.
Begrenzte Standardisierung
Anders als bei relationalen Datenbanken gibt es für Graphdatenbanken noch keine einheitlichen Standards. Dies kann zu Vendor-Lock-in führen.
Hoher Speicherbedarf
Die Speicherung von Beziehungsinformationen kann bei sehr großen Datensätzen zu erhöhtem Speicherbedarf führen, insbesondere wenn viele redundante Verbindungen existieren.
Vergleich führender Graphdatenbank-Systeme
Der Markt für Graphdatenbanken wächst rasant und wird bis 2029 auf 9,59 Milliarden USD geschätzt. Hier die wichtigsten Player:
| Datenbank | Stärken | Einsatzgebiet | Lizenzmodell |
| Neo4j | Marktführer, umfangreiche Tools, aktive Community | Enterprise-E-Commerce, soziale Netzwerke | Community + Commercial |
| Amazon Neptune | Cloud-nativ, vollständig verwaltet, AWS-Integration | Cloud-basierte Anwendungen | Pay-per-Use |
| ArangoDB | Multi-Model (Graph, Dokument, Key-Value) | Flexible Anwendungen mit verschiedenen Datentypen | Open Source + Enterprise |
| Azure Cosmos DB | Globale Verteilung, Multi-API-Support | Microsoft-Umgebungen, internationale Skalierung | Cloud-Service |
Performance-Vergleich in der Praxis
Eine aktuelle Benchmark-Studie aus 2024 zeigt, dass Neo4j bei komplexen Traversierungsabfragen führt, während Amazon Neptune bei Cloud-nativen Szenarien punktet. ArangoDB überzeugt durch Flexibilität bei gemischten Workloads.
Graphdatenbanken vs. relationale Datenbanken im E-Commerce
Der Vergleich zwischen Graphdatenbanken und traditionellen relationalen Systemen verdeutlicht die unterschiedlichen Stärken:
Relationale Datenbanken
– Vorteile: Etablierte Standards (SQL), hohe Konsistenz (ACID), umfangreiche Tool-Landschaft
– Nachteile: Langsame JOIN-Operationen bei komplexen Beziehungen, starre Schemastrukturen
Graphdatenbanken
– Vorteile: Schnelle Traversierung, flexible Schemaevolution, natürliche Modellierung von Beziehungen
– Nachteile: Weniger Standards, spezialisiertes Know-how erforderlich
Für E-Commerce-Empfehlungssysteme sind Graphdatenbanken klar im Vorteil, da sie die für Personalisierung entscheidenden Beziehungsmuster deutlich effizienter verarbeiten können.
Praktische Implementierung und Erfolgsgeschichten
Die erfolgreiche Einführung einer Graphdatenbank folgt typischerweise diesem Vorgehen:
1. Datenmodell-Design
Definieren Sie zunächst Ihre Entitäten (Kunden, Produkte, Kategorien) und deren Beziehungen. Berücksichtigen Sie dabei sowohl explizite Verbindungen (Käufe) als auch implizite Muster (Browsing-Verhalten).
2. Schrittweise Migration
Beginnen Sie mit einem spezifischen Anwendungsfall wie Produktempfehlungen, bevor Sie das gesamte System migrieren. Dies minimiert Risiken und ermöglicht iteratives Lernen.
3. Hybrid-Ansätze nutzen
Viele Unternehmen kombinieren Graphdatenbanken mit bestehenden Systemen. Transaktionale Daten bleiben oft in relationalen Datenbanken, während Beziehungsanalysen im Graph stattfinden.
Erfolgsgeschichte: Adidas
Der Sportartikelhersteller adidas nutzt Neo4j für sein Masterdatenmanagement und konnte dadurch isolierte Datensilos erfolgreich verknüpfen. Thomas Müller-Fans erhalten gezielt Fußball-Produktempfehlungen, während Basketball-Enthusiasten teamspezifische Inhalte präsentiert bekommen.
„Durch die Graphdatenbank können wir erstmals das komplette Kundenprofil in Echtzeit verstehen und entsprechend personalisierte Empfehlungen ausspielen.“
— Adidas Digital Analytics Team
Implementierungs-Roadmap
- Proof of Concept (2-4 Wochen): Testen Sie die Graphdatenbank mit einem kleinen Datensatz
- Pilot-Projekt (2-3 Monate): Implementieren Sie einen spezifischen Use Case
- Schrittweise Ausweitung (6-12 Monate): Erweitern Sie sukzessive auf weitere Anwendungsbereiche
- Full Scale (12+ Monate): Integration in die Gesamtarchitektur
Die moderne E-Commerce-Landschaft wird zunehmend von der Fähigkeit geprägt, Kundenbeziehungen in Echtzeit zu verstehen und zu nutzen. Graphdatenbanken bieten hierfür die technologische Grundlage und ermöglichen es Unternehmen, sich vom Wettbewerb abzuheben. Trotz der Implementierungsherausforderungen überwiegen die Vorteile deutlich, insbesondere für Unternehmen mit komplexen Produktkatalogen und diversifizierten Kundenstämmen.
Der Schlüssel zum Erfolg liegt in einer durchdachten Implementierungsstrategie, die sowohl technische als auch organisatorische Aspekte berücksichtigt. Unternehmen, die heute in Graphdatenbank-Technologie investieren, schaffen sich einen entscheidenden Wettbewerbsvorteil für die datengetriebene Zukunft des E-Commerce.


