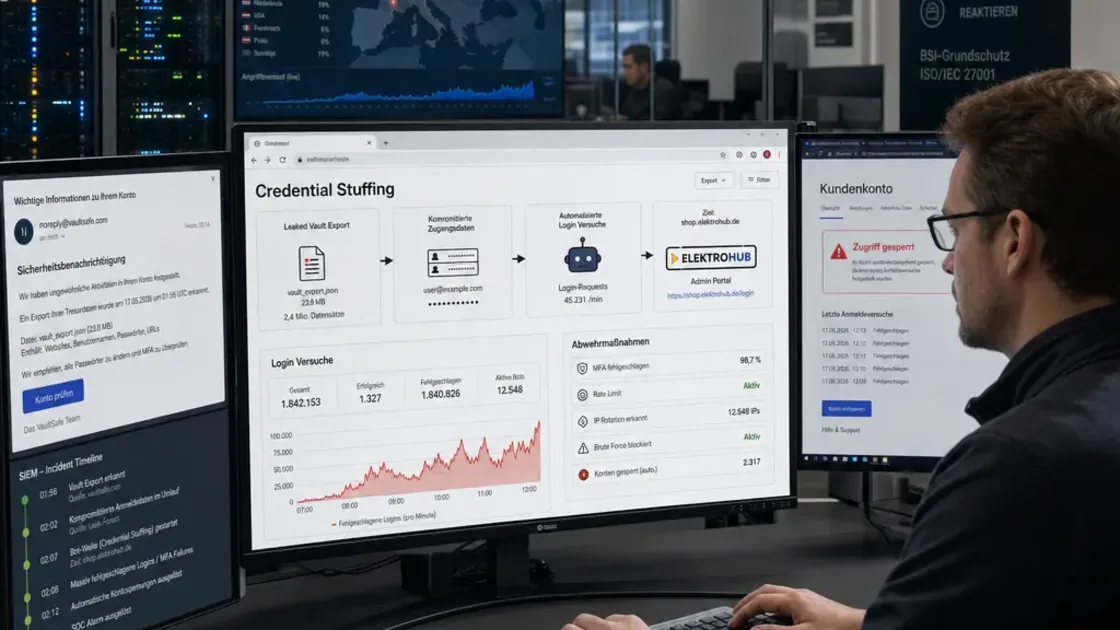
Ende Juni 2026 meldete ein europäischer Passwort-Manager-Anbieter einen Abfluss von Metadaten – keine Tresor-Inhalte, aber genug, um Kriminellen Angriffsflächen zu liefern. Seither häufen sich Reports über automatisierte Credential-Stuffing-Wellen gegen Banking-Portale, Shops und Unternehmensnetze. Der Clou: Die eigentliche Gefahr kommt nicht aus dem Leak selbst, sondern aus der Maschinerie, die danach anläuft.
Ein Metadaten-Leak klingt erstmal harmlos. Keine Passwörter im Klartext, kein Tresor-Dump, nur Account-IDs, Nutzungsmuster, vielleicht E-Mail-Adressen. Wenig überraschend nutzen Angreifer genau solche Datenreste, um bestehende Combolists anzureichern und gezielter zuzuschlagen. Das Pikante daran: Wer ohnehin schon von einem der zahlreichen Mega-Leaks der vergangenen Jahre betroffen war, liefert mit dem neuen Datensatz das fehlende Puzzleteil für eine Kontoübernahme. Zusammen ergibt das eine Angriffskette, die sich technisch exakt beschreiben lässt – und genau darum geht es in diesem Deep-Dive.
Der Vorfall Ende Juni 2026: Metadaten sind kein Trost
Anbieter von Passwort-Managern werben gerne mit Zero-Knowledge-Verschlüsselung: Selbst bei einem Server-Einbruch bleiben die eigentlichen Tresor-Inhalte unlesbar, weil der Schlüssel nie den Client verlässt. Das ist technisch meist korrekt. Nur: Metadaten sind kein Beiwerk. Wer weiß, welche Domains ein Nutzer im Tresor gespeichert hat, kennt dessen digitales Leben – Bank, Streaming, Cloud, Behördenportal. Genau diese Informationen sind laut aktuellen Berichten bei dem Vorfall abgeflossen.
Die Reaktion der Kriminellen folgte binnen Tagen. Sicherheitsteams meldeten spürbar mehr automatisierte Login-Versuche gegen Dienste, deren Nutzerbasis sich mit der des betroffenen Passwort-Managers überschneidet. Das ist kein Zufall, sondern Arbeitsteilung: Leak-Daten werden aggregiert, mit bestehenden Datenbanken aus früheren Vorfällen kombiniert und in neue Combolists gepackt. Aus einer Meldung über Metadaten wird so binnen Tagen ein handfestes Problem für ganz andere Plattformen.
Credential Stuffing versus Brute Force: der feine, aber brisante Unterschied
Beide Begriffe werden in der Berichterstattung gerne synonym verwendet – fachlich ist das falsch, und der Unterschied hat direkte Konsequenzen für die Abwehr. Ein klassischer Brute-Force-Angriff probiert systematisch Passwortvarianten gegen ein einzelnes Konto, ohne Vorwissen über das tatsächliche Passwort. Credential Stuffing dagegen nutzt bereits bekannte, aus Leaks stammende Kombinationen aus Benutzername und Passwort und testet sie massenhaft gegen viele verschiedene Dienste.
Der Unterschied ist entscheidend: Gegen Brute Force helfen Ratenbegrenzung und Kontosperrung nach X Fehlversuchen relativ zuverlässig. Gegen Credential Stuffing helfen sie kaum, weil jeder einzelne Versuch mit hoher Wahrscheinlichkeit ein gültiges Passwort enthält – nur eben für ein anderes Konto beim gleichen Nutzer. Die Erfolgsquote pro Versuch liegt zwar nur bei ein bis zwei Prozent, bei Millionen automatisierter Anfragen reicht das für massenhafte Kontoübernahmen. Genau diese Rechnung macht Credential Stuffing zur wirtschaftlich attraktivsten Angriffsform der Gegenwart, wenn Passwort-Kompromittierung im großen Stil vorliegt, wie auch die Einordnung zu aktuellen Ansätzen für eine sicherere digitale Welt deutlich macht.
Persönlich halte ich die ständige Verwechslung beider Begriffe für mehr als Semantik-Nörgelei: Wer die falsche Abwehrstrategie gegen das falsche Angriffsmuster aufbaut, verschwendet Budget und Vertrauen gleichermaßen. Ein Beispiel aus der Praxis verdeutlicht das: Ein Online-Shop, der ausschließlich auf klassische Kontosperrung nach fünf Fehlversuchen setzt, bleibt gegen Brute Force gut geschützt – gegen Credential Stuffing bleibt die Tür jedoch offen, weil jeder einzelne Versuch bereits ein korrektes Passwort enthält und daher kaum als „Fehlversuch“ auffällt, solange die zugehörige E-Mail-Adresse nicht im System hinterlegt ist.
Die Angriffskette im Detail: Von Leak zu Kontoübernahme
Nach einem Datenabfluss läuft eine mittlerweile hochgradig standardisierte Kette an. Erstens: Der Breach selbst, bei dem Zugangsdaten, Metadaten oder beides in Untergrundforen oder offenen Dumps landen. Zweitens: Die Aufbereitung zu Combolists, in denen mehrere Leaks zusammengeführt werden, oft ergänzt durch aktuelle Infostealer-Logs von infizierten Endgeräten. Erst kürzlich wurden laut Berichten über die Sicherheitsdatenbank Have I Been Pwned 124 Millionen einzigartige Passwörter und 56 Millionen E-Mail-Adressen aus solchen Infostealer-Logs neu eingespielt, wie unter anderem Forbes berichtete.
Drittens: Automatisierte Tests gegen fremde Login-Endpunkte. Tools wie OpenBullet oder angepasste Skript-Runner injizieren Combolists in Anmeldeformulare und APIs, oft über Residential-Proxy-Netze, die Anfragen auf tausende IP-Adressen verteilen. Viertens verstärkt Passwort-Wiederverwendung den Effekt massiv: Aus einem einzigen kompromittierten Konto lassen sich potenziell Dutzende weitere übernehmen, wenn Nutzer dasselbe Passwort mehrfach verwenden. Fünftens folgt die Post-Compromise-Phase: Zahlungsbetrug, Datenexfiltration, manchmal die Vorbereitung weiterer Angriffe wie Ransomware.
Das Bemerkenswerte an dieser Kette ist ihre Geschwindigkeit. Zwischen Leak und ersten massiven Stuffing-Wellen liegen inzwischen oft nur Stunden bis wenige Tage – nicht Wochen, wie es vor einigen Jahren noch üblich war. Diese Beschleunigung hat einen einfachen Grund: Die Aufbereitung von Rohdaten zu verwertbaren Combolists ist selbst weitgehend automatisiert. Spezialisierte Untergrundakteure bieten diesen Schritt inzwischen als Dienstleistung an, ähnlich einem Software-as-a-Service-Modell, nur eben für kriminelle Zwecke. Wer sich fragt, warum ausgerechnet kleine und mittelständische Anbieter oft zuerst betroffen sind, findet die Antwort in dieser Arbeitsteilung: Große Plattformen mit ausgereiftem Bot-Management werden zwar ebenfalls angegriffen, bieten aber schlicht weniger leicht erreichbare Erfolgsquoten als kleinere Portale ohne entsprechende Schutzmechanismen.
Erkennungslogiken: Login-Anomalien, geografische Sprünge, Timing-Muster
Wer automatisierte Angriffsketten erkennen will, braucht mehr als eine einzelne Kennzahl. Drei Signalklassen haben sich in der Praxis als besonders verlässlich erwiesen.
Geografische Sprünge und Impossible Travel
Meldet sich ein Konto binnen wenigen Minuten aus Hamburg und dann aus Manila an, ist das physisch unmöglich – ein klassisches „Impossible Travel“-Signal. Automatisierte Systeme prüfen dafür Geolokation, Zeitstempel und realistische Reisegeschwindigkeit zwischen zwei Logins. Kombiniert mit auffälligen IP-Ranges, etwa Cluster aus bekannten Proxy-Diensten oder Rechenzentrums-IPs statt üblicher Heim-Anschlüsse, entsteht ein belastbares Anomalie-Profil. Wichtig dabei: Einzelne Ausreißer, etwa durch VPN-Nutzung, sind normal. Erst die Häufung über viele Konten hinweg zeigt ein Muster.
Timing-Muster und Bot-Signaturen
Menschen tippen ihre Zugangsdaten nicht mit maschineller Präzision ein. Anmeldeversuche, die im exakt gleichen zeitlichen Abstand erfolgen, oder Login-Requests ohne die üblichen Verzögerungen durch Seitenladezeiten und Interaktion, sind starke Hinweise auf Skripte. Dazu kommen identische oder synthetische User-Agents, fehlende oder manipulierte Browser-Fingerprints und eine dramatisch erhöhte Fehlerrate bei Logins innerhalb kurzer Zeitfenster, ohne dass es dafür eine plausible Erklärung wie eine Marketingkampagne gibt. Professionelle Angreifer versuchen inzwischen, menschliches Verhalten zu simulieren – etwa durch künstliche Pausen oder Captcha-Solving-Dienste. Das erschwert die Erkennung, macht sie aber nicht unmöglich, wenn mehrere Signalklassen kombiniert werden.
Ein Drittel aller weltweiten Anmeldeversuche erfolgt laut Branchenanalysen inzwischen nicht mit frisch eingegebenen, sondern mit zuvor erbeuteten Zugangsdaten, wie IT-Daily berichtet. Diese Zahl allein zeigt, warum reine Login-Erfolgsraten als Kennzahl nicht mehr ausreichen – die Masse der Versuche selbst ist bereits das Problem. Ergänzend lohnt sich ein Blick auf Session- und Device-Fingerprinting: Selbst wenn ein Angreifer die korrekten Zugangsdaten besitzt, unterscheidet sich das verwendete Gerät, der Browser-Stack und das Verhalten nach dem Login oft deutlich von dem des legitimen Nutzers. Wer diese Signale zusätzlich zu den bereits genannten Mustern auswertet, gewinnt eine weitere, sehr belastbare Erkennungsebene, die sich schwerer täuschen lässt als reine IP- oder Timing-Analysen.

Zahlen, die wehtun: Wie industrialisiert Credential Stuffing wirklich ist
Die Dimensionen sind inzwischen kaum noch greifbar. Nach Angaben aus aktuellen Branchenberichten kursieren weltweit über 24 Milliarden gestohlene Zugangsdaten-Paare, ein Teil davon stammt aus einem Mega-Leak, über den unter anderem CHIP berichtete. Angreifer testen solche Datensätze in einem Umfang, der schlicht industriell ist – Branchenschätzungen sprechen von tens Milliarden automatisierten Login-Versuchen pro Monat weltweit.
Das Pikante daran: Trotz einer Erfolgsquote von nur etwa 0,1 bis 2 Prozent pro Versuch reicht die schiere Masse für massenhafte Kontoübernahmen. Sicherheitsanbieter berichten von einer deutlichen Zunahme bei Credential-Theft-Vorfällen im Jahresvergleich. Für Unternehmen bedeutet das: Selbst eine winzige Erfolgsquote wird bei Millionen von Versuchen zu einem realen Betrugsproblem, das sich in Chargebacks, Support-Kosten und Reputationsschäden niederschlägt.
Diese wirtschaftliche Dimension wird in der öffentlichen Diskussion oft unterschätzt. Jede erfolgreiche Kontoübernahme zieht Folgekosten nach sich: Support-Anfragen betroffener Nutzer, mögliche Rückbuchungen bei Zahlungsbetrug, im schlimmsten Fall Bußgelder wegen unzureichender Schutzmaßnahmen nach DSGVO. Gerade der Zusammenhang zwischen schlechten Passwort-Gewohnheiten und der Wucht solcher Angriffswellen wird in Berichten regelmäßig thematisiert – wer wissen will, wie tief das Problem auf Nutzerseite verwurzelt ist, findet dazu weitere Einordnung in einem Report, der vor schlechten Passwort-Praktiken warnt. Die dort beschriebenen Muster – Wiederverwendung, triviale Variationen, fehlende Aktualisierung nach bekannten Leaks – erklären zu großen Teilen, warum Credential Stuffing trotz jahrelanger Warnungen weiterhin so wirksam bleibt.
Abwehrstrategien: 2FA-Enforcement und Bot-Management
Die naheliegendste Verteidigungslinie ist die konsequente Durchsetzung von Zwei-Faktor-Authentifizierung – und zwar nicht als Option, sondern als Pflicht für alle Nutzerkonten. Wichtig dabei: SMS-basierte 2FA gilt inzwischen als vergleichsweise schwach, weil SIM-Swapping und das Abfangen von SMS-Codes technisch machbar sind. App-basierte Einmalcodes oder hardwaregestützte Verfahren nach dem FIDO2-Standard bieten deutlich robusteren Schutz.
Für Unternehmen kommt eine zweite Ebene hinzu: Bot-Management und Web Application Firewalls, die speziell auf Credential-Stuffing-Muster trainiert sind. Einfache IP-Blocklisten reichen längst nicht mehr, weil Angreifer ihre Anfragen über tausende wechselnde Adressen verteilen. Wirksamer sind Systeme, die Geräte-Fingerprints, Verhaltensmuster und Threat-Intelligence-Feeds mit bekannten Leak-Quellen kombinieren. Wer zusätzlich bekannte kompromittierte Passwörter aktiv gegen die eigene Nutzerdatenbank abgleicht – ähnlich dem Prinzip von Have I Been Pwned – kann betroffene Konten proaktiv zur Passwortänderung zwingen, bevor ein Angreifer überhaupt zuschlägt.
Kleine Unternehmen ohne eigenes Security-Team unterschätzen diesen Aufwand oft. Muss es wirklich ein komplettes Bot-Management-System sein? Nicht zwingend – aber ein Login-Monitoring, das ungewöhnliche Fehlerraten und geografische Sprünge meldet, lässt sich auch mit überschaubarem Budget realisieren, etwa über vorkonfigurierte Module gängiger Hosting- und Cloud-Anbieter. Ein Gegenargument, das in Diskussionen häufig fällt: Zu aggressive Schutzmaßnahmen wie strikte Captchas oder zusätzliche Verifizierungsschritte erhöhen die Absprungrate legitimer Nutzer und schaden dem Geschäft. Dieses Risiko ist real, lässt sich aber durch risikobasierte Verfahren entschärfen, bei denen zusätzliche Hürden nur bei tatsächlich verdächtigem Verhalten greifen – etwa bei ungewöhnlicher Geolokation oder bei Logins aus bekannten Proxy-Netzen – statt pauschal jeden Nutzer zu belasten.
Passwordless-Transition: Ausweg oder nur Verschiebung des Problems?
Passkeys und WebAuthn-basierte Anmeldeverfahren gelten inzwischen als die technisch sauberste Antwort auf das Grundproblem: Wenn es kein wiederverwendbares Passwort mehr gibt, das gestohlen werden kann, verliert Credential Stuffing seine Grundlage komplett. Die Anmeldung erfolgt über kryptografische Schlüsselpaare, bei denen der private Schlüssel das Gerät nie verlässt – ein klassischer Leak-und-Stuffing-Zyklus wird technisch unmöglich.
Die Realität sieht durchwachsener aus. Die Umstellung auf Passkeys läuft bei vielen großen Plattformen parallel zu klassischen Passwort-Logins, was bedeutet: Solange die alte Tür offen bleibt, hilft die neue, sicherere Tür wenig gegen Angreifer, die einfach den bequemeren Weg nehmen. Für Unternehmen bedeutet eine echte Passwordless-Transition daher nicht nur technische Umstellung, sondern auch den Mut, alte Login-Pfade konsequent abzuschalten – ein Schritt, den viele aus Angst vor Nutzerfrust bislang scheuen.
Meiner Einschätzung nach wird genau diese Halbherzigkeit zum eigentlichen Sicherheitsrisiko der nächsten Jahre: Zwei parallele Anmeldewege bedeuten zwei parallele Angriffsflächen, nicht die Summe ihrer Schutzwirkung. Hinzu kommt ein praktisches Problem, das in der Debatte gerne übergangen wird: Passkeys sind an Geräte oder Geräte-Ökosysteme gebunden, was den Wechsel zwischen Plattformen oder den Verlust eines Geräts zu einer neuen Herausforderung macht. Anbieter arbeiten an Synchronisationslösungen über Cloud-Dienste, doch genau diese Synchronisation schafft wiederum neue Angriffsflächen, wenn das zugrunde liegende Cloud-Konto selbst nicht ausreichend geschützt ist. Der Umstieg löst das Grundproblem also nicht automatisch, er verschiebt es an eine andere, im besten Fall besser gesicherte Stelle.
Handlungsschritte für Endnutzer und kleine Unternehmen
Wer nach einem Vorfall wie dem Ende Juni 2026 bekannt gewordenen Metadaten-Leak nicht wochenlang jedes einzelne Konto prüfen will, sollte priorisieren. Zuerst die Konten mit dem größten Schadenspotenzial: E-Mail-Postfach, da es meist als Recovery-Kanal für alle anderen Dienste dient, dann Online-Banking, Cloud-Speicher und geschäftskritische Zugänge. Für jedes dieser Konten gilt: individuelles, langes Passwort, wenn möglich Passkey statt klassischem Login, und Zwei-Faktor-Authentifizierung mit App oder Hardware-Token statt SMS.
Ein Passwort-Manager bleibt trotz solcher Vorfälle sinnvoll – die Alternative, überall dasselbe Passwort zu verwenden, ist nachweislich das größere Risiko. Entscheidend ist die Architektur: Zero-Knowledge-Verschlüsselung, transparente Kommunikation im Ernstfall und regelmäßige, öffentlich einsehbare Sicherheitsaudits. Kleine Unternehmen sollten zusätzlich prüfen, ob ihre Login-Systeme grundlegende Anomalie-Erkennung bieten – viele Cloud- und Shop-Plattformen liefern entsprechende Bausteine bereits mit, sie müssen nur aktiviert werden. Wer auf Nummer sicher gehen will, richtet Benachrichtigungen für neue Logins, geografische Auffälligkeiten und fehlgeschlagene Anmeldeversuche ein – kostenlos, aber wirkungsvoll.
Ein praktisches Szenario zur Einordnung: Ein mittelständischer Online-Shop mit einigen tausend Kundenkonten stellt nach einem bekannt gewordenen Leak eines häufig genutzten Drittanbieters fest, dass die Fehlerrate bei Logins über Nacht deutlich steigt, ohne erkennbare Kampagne oder Aktion im Hintergrund. Statt panisch alle Konten zu sperren, empfiehlt sich ein abgestuftes Vorgehen: temporäre Erzwingung eines zweiten Faktors für Konten mit auffälligem Muster, gezielte Benachrichtigung betroffener Nutzer zur Passwortänderung und parallele Beobachtung der IP- und Geolokationsverteilung über einige Tage. So lässt sich die Angriffswelle eindämmen, ohne den gesamten Kundenstamm unnötig zu verschrecken. Wer zusätzlich prüfen möchte, in welchem Ausmaß eigene Zugangsdaten bereits im Umlauf sind, findet über Berichte zu Identitätsdiebstahl und Identity Abuse weitere Anhaltspunkte, wie stark einzelne Identitäten inzwischen fragmentiert über verschiedene Leaks verteilt sind.
Was bleibt?
Der Metadaten-Leak vom Sommer 2026 zeigt exemplarisch, wie wenig es braucht, um eine Lawine automatisierter Angriffsketten auszulösen. Credential Stuffing ist längst kein Nischenphänomen für große US-Konzerne mehr, sondern trifft KMU-Portale, Behördenzugänge und private Konten gleichermaßen. Die technischen Werkzeuge zur Erkennung existieren, ebenso die Abwehrstrategien von 2FA-Enforcement bis Passwordless-Transition. Die eigentliche Frage ist, ob genug Anbieter und Nutzer bereit sind, die bequemen alten Pfade wirklich zu schließen – oder ob der nächste Leak wieder nur zur nächsten Schlagzeile wird, bevor sich etwas ändert.


Was halten Sie von dem Thema? Hier können Sie mit anderen Leserinnen und Lesern ins Gespräch gehen.
Mitreden & diskutieren
Ihre Meinung zählt — teilen Sie Gedanken, Fragen oder Erfahrungen zu diesem Artikel.