Der Europäische Datenschutzausschuss belässt es nicht mehr bei Grundsatzpapieren. Mit der Opinion 28/2024 zu KI-Modellen und den Guidelines 4/2024 zu Künstlicher Intelligenz und Datenschutz hat das EDPB detaillierte technische Anforderungen formuliert – von Resistenztests gegen Angriffe auf Trainingsdaten bis zur getrennten Bewertung jeder einzelnen KI-Phase. Nicht verbindlich im Sinne eines Gesetzes, aber faktisch der Massstab, an dem Aufsichtsbehörden künftig prüfen. Wer das ignoriert, riskiert mehr als ein Bussgeld.
Der Anlass: Aufsichtsbehörden werden konkret
Jahrelang bewegten sich Datenschutzbehörden bei KI-Themen auf der Ebene allgemeiner Prinzipien: Datenminimierung, Zweckbindung, Transparenz. Klang gut, half aber wenig, wenn Entwicklerteams konkret wissen wollten, welche technische Massnahme im Trainingsprozess tatsächlich ausreicht. Diese Phase ist vorbei. Mit der Opinion 28/2024 vom 18. Dezember 2024 und den ergänzenden Guidelines 4/2024 hat das EDPB erstmals technische Prüfkriterien formuliert, die sich direkt in Architekturentscheidungen übersetzen lassen. Es geht nicht mehr um das Ob, sondern um das Wie.
Parallel drängen EDPB und der Europäische Datenschutzbeauftragte (EDPS) in einer gemeinsamen Stellungnahme auf eine straffere Umsetzung des AI Acts – mit stärkeren Schutzmechanismen und einer klaren Rolle für Datenschutzbehörden bei der technischen Prüfung von Hochrisiko-KI. Diese Standardisierung fällt in eine Phase, in der ohnehin zentrale AI-Act-Pflichten greifen: Transparenzanforderungen für Foundation-Modelle sind seit August 2025 aktiv, weitere Pflichten für Hochrisiko-Systeme laufen sukzessive an. Die EDPB-Vorgaben zur Datenschutz KI-Architektur docken direkt an diesen Zeitplan an, statt eine Nebenschiene zu betreiben.
Anonymität ist eine Behauptung, die belegt werden muss
Der wohl folgenreichste Punkt der Opinion 28/2024: Ein KI-Modell, das mit personenbezogenen Daten trainiert wurde, ist nicht automatisch anonym – auch dann nicht, wenn die Trainingsdaten vorab pseudonymisiert wurden. Das EDPB verlangt eine Einzelfallprüfung entlang zweier Kriterien: Wie wahrscheinlich ist es, Personen zu identifizieren, deren Daten im Training verwendet wurden? Und lassen sich personenbezogene Informationen durch gezielte Anfragen oder Angriffe aus dem Modell extrahieren?
Für Entwicklungsteams bedeutet das konkrete Arbeit statt Absichtserklärung. Gefordert werden dokumentierte Anonymisierungsmassnahmen wie Differential Privacy oder Aggregation, dazu Resistenztests gegen bekannte Angriffsklassen – Membership-Inference-Angriffe, Modellrekonstruktion, Prompt-Inversion – sowie eine nachvollziehbare Prüfung, ob eine Datenschutzfolgenabschätzung erforderlich ist. Wer sein Modell als „anonym“ vermarktet, ohne diese Tests durchgeführt zu haben, argumentiert an der Aufsichtspraxis vorbei. Das betrifft übrigens nicht nur öffentlich bereitgestellte Modelle: Die Opinion adressiert ausdrücklich auch intern genutzte Systeme. Ein Modell, das unter Verstoss gegen die Datenschutz-Grundverordnung entwickelt wurde, darf im Zweifel gar nicht oder nur eingeschränkt weiter betrieben werden – unabhängig davon, ob es je einen externen Nutzer gesehen hat.
Wie gross die Kluft zwischen behaupteter und tatsächlich nachgewiesener Anonymität in der Praxis bereits ist, zeigen aktuelle Bestandsaufnahmen zu Sicherheitsrisiken von KI-Assistenten im laufenden Betrieb. Dort wird deutlich, dass viele produktiv eingesetzte Systeme genau jene Resistenztests nie durchlaufen haben, die das EDPB inzwischen faktisch voraussetzt – ein Umstand, der bislang selten Konsequenzen hatte, weil schlicht niemand systematisch danach fragte.
Jede KI-Phase ist eine eigene Verarbeitung
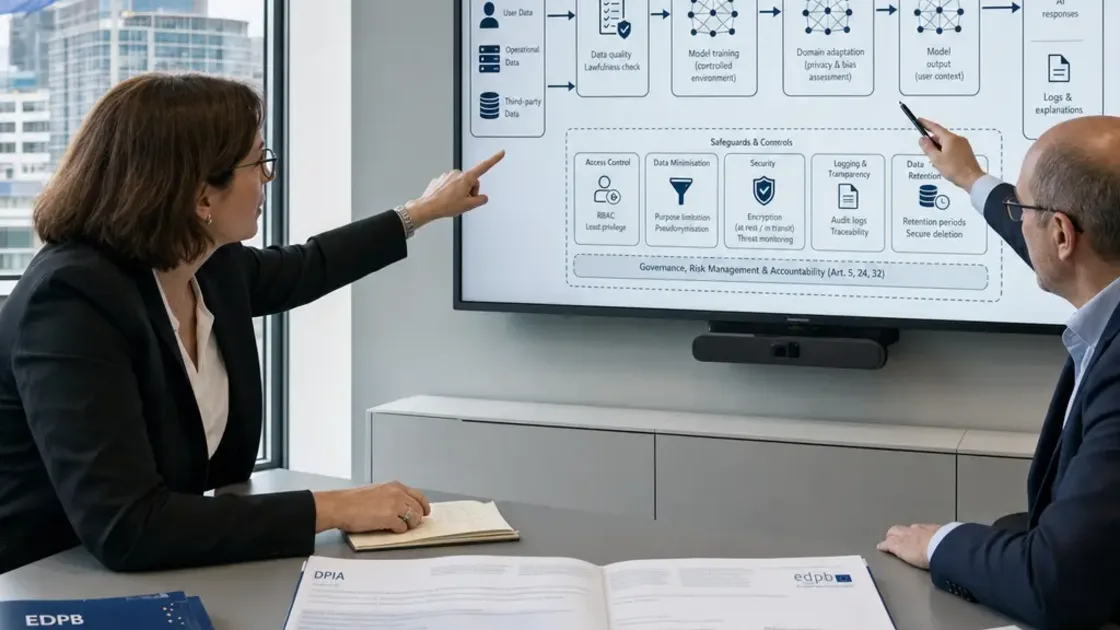
Die Guidelines 4/2024 etablieren ein Prinzip, das viele bestehende KI-Pipelines technisch in Frage stellt: Datensammlung, Training, Fine-Tuning, Inferenz und laufendes Monitoring sind jeweils eigenständige Verarbeitungsvorgänge. Jede Phase braucht eine eigene Rechtsgrundlage, eigene technische und organisatorische Massnahmen, eigene Zugriffsrechte und eine eigene Protokollierung. Ein einziges Datenschutzkonzept für das gesamte Modell-Lifecycle reicht aus Sicht der Behörde nicht mehr aus.
Praktisch heisst das: Teams müssen ihre KI-Architektur modular denken. Wer Rohdaten sammelt, braucht eine andere Rechtfertigung als wer ein bereits trainiertes Modell für ein neues Anwendungsfeld feinjustiert. Wer ein System im Produktivbetrieb überwacht, muss diese Überwachung selbst wieder datenschutzrechtlich einordnen, weil dabei häufig neue personenbezogene Daten entstehen – etwa Nutzungsprotokolle oder Feedback-Signale. Für Hochrisiko-Anwendungen, etwa im Recruiting oder bei automatisierten Leistungsbewertungen, ist eine gesonderte Datenschutzfolgenabschätzung inzwischen der Regelfall statt die Ausnahme. Genau an dieser Stelle trifft die technische Standardisierung auf die ohnehin laufende Pflicht zur DPIA-Vorlage im Rahmen der AI-Act-Compliance – zwei Rechtsrahmen, die inhaltlich zusammenwachsen, aber jeweils eigene Dokumentationspfade verlangen.
Berechtigtes Interesse als Rechtsgrundlage – mit technischem Preis
Das EDPB akzeptiert „berechtigtes Interesse“ grundsätzlich als Rechtsgrundlage für das Training von KI-Modellen mit personenbezogenen Daten. Das ist praxisnäher, als es zunächst klingt, denn Einwilligungen für grosse Trainingsdatensätze sind kaum skalierbar. Die Anerkennung ist jedoch an Bedingungen gekoppelt, die technische Konsequenzen haben. Der Verarbeitungszweck muss klar, gegenwärtig und real sein – vage Formulierungen wie „Modellverbesserung“ reichen nicht. Die Verarbeitung muss erforderlich sein, das heisst: Es muss geprüft werden, ob weniger invasive Alternativen wie anonymisierte oder aggregierte Daten den Zweck ebenso erfüllen könnten. Und am Ende steht eine Interessenabwägung, die dokumentiert werden muss.
Wer diese drei Schritte ernst nimmt, landet unweigerlich bei technischer Datenminimierung: weniger Merkmale, kürzere Speicherfristen, Löschroutinen, die nicht erst bei Beschwerden greifen. Privacy by Design ist hier keine Marketingfloskel, sondern eine Anforderung, die bereits in Trainings- und Fine-Tuning-Pipelines eingebaut sein muss, nicht nachträglich aufgesetzt. Wer sich das spart, verschiebt das Risiko lediglich – auf den Moment einer Prüfung durch die Aufsichtsbehörde.

DSGVO und AI Act: Ein gemeinsames Governance-System statt Parallelprüfung
Besonders bemerkenswert an den Guidelines 4/2024 ist die ausdrückliche Forderung, DSGVO-Prüfungen und AI-Act-Prüfungen nicht länger getrennt zu behandeln, sondern in ein gemeinsames Governance-System zu integrieren. Für Unternehmen bedeutet das eine klare Rollen- und Verantwortlichkeitsmatrix: Wer ist Verantwortlicher im Sinne der DSGVO, wer Anbieter oder Betreiber im Sinne des AI Acts – und wo überschneiden sich diese Rollen technisch?
Diese Verzahnung ist folgerichtig, aber aufwendig. Technische Dokumentation muss künftig beide Rechtsrahmen gleichzeitig bedienen: Datenschutzfolgenabschätzung nach Artikel 35 DSGVO und technische Dokumentation nach den Vorgaben für Hochrisiko-KI-Systeme sind keine getrennten Ordner mehr, sondern im Idealfall ein durchgängiger Nachweis. Wer heute noch zwei separate Compliance-Teams betreibt, die sich nicht abstimmen, wird bei der nächsten Prüfung Lücken produzieren, die vermeidbar gewesen wären. Genau diese Lücken sind es, die aus Sicht vieler Aufsichtsbehörden bislang zu wenig adressiert wurden – ein Punkt, den auch Analysen zu verbleibenden Datenschutz-Vertraulichkeitslücken in KI-Systemen regelmässig aufgreifen.
Praxisszenario: So könnte eine Prüfung ablaufen
Um zu verstehen, was die neuen Anforderungen im Alltag bedeuten könnten, lohnt ein vorsichtiges Gedankenspiel. Ein mittelständisches Softwarehaus setzt ein Sprachmodell ein, das mit Kundendaten feinjustiert wurde, um automatisierte Support-Antworten zu generieren. Eine Aufsichtsbehörde fragt im Rahmen einer Routineprüfung nach dem Nachweis, dass Kundendaten im Modell nicht rekonstruierbar sind. Liegt kein dokumentierter Resistenztest vor, bleibt dem Unternehmen wenig Spielraum: Es müsste im Nachhinein belegen, was es hätte vorab prüfen sollen – ein Prozess, der deutlich aufwendiger ist als eine von Anfang an eingeplante Testroutine.
In einem zweiten, ebenso hypothetischen Fall hat ein Unternehmen seine Trainingspipeline von Beginn an in einzelne Phasen zerlegt und für jede Phase eine eigene Rechtsgrundlage samt Protokollierung hinterlegt. Bei einer Anfrage der Behörde kann es innerhalb kurzer Zeit nachvollziehbar darlegen, welche Daten in welcher Phase zu welchem Zweck verarbeitet wurden. Der Unterschied zwischen beiden Szenarien liegt nicht in der Grösse des Unternehmens oder der Komplexität des Modells, sondern allein darin, ob Datenschutz von Anfang an mitgedacht oder nachträglich aufgesetzt wurde. Solche Szenarien sind naturgemäss vereinfacht, sie zeigen aber, in welche Richtung sich die Beweislast verschiebt.
Folgen für Unternehmen unterschiedlicher Grösse
Die technischen Anforderungen des EDPB treffen nicht alle Marktteilnehmer gleich. Grosse Konzerne verfügen in der Regel über eigene Rechtsabteilungen, spezialisierte Datenschutzteams und die Ressourcen, um Resistenztests, Dokumentationspflichten und die Verzahnung von DSGVO und AI Act parallel zu bearbeiten. Für sie ist die Standardisierung vor allem ein zusätzlicher, aber planbarer Aufwand, der sich in bestehende Compliance-Strukturen integrieren lässt.
Für kleinere Unternehmen und Start-ups sieht die Lage anders aus. Wer mit begrenztem Personal ein KI-Produkt entwickelt, muss nun zusätzlich Kapazitäten für Anonymitätsnachweise, phasenweise Dokumentation und eine gemeinsame Governance-Struktur aufbringen – oft ohne eigene Rechtsabteilung im Rücken. Das kann dazu führen, dass technisch durchaus solide Produkte an fehlender Dokumentation scheitern, nicht an mangelnder Sicherheit. Wer in dieser Phase klug vorgeht, bindet Datenschutzfragen von der ersten Architekturentscheidung an ein und vermeidet damit teure Nachbesserungen. Externe Beratung oder standardisierte Open-Source-Tools für Resistenztests können hier helfen, den Aufwand zu begrenzen, ersetzen aber nicht die interne Auseinandersetzung mit der eigenen Datenverarbeitung.
Was Unternehmen jetzt technisch umsetzen sollten
Aus den EDPB-Vorgaben lässt sich eine Reihe konkreter Schritte ableiten, die weit über Absichtserklärungen hinausgehen. Erstens: Jede KI-Pipeline sollte in ihre einzelnen Phasen zerlegt und für jede Phase separat dokumentiert werden, welche Rechtsgrundlage gilt und welche technischen Massnahmen greifen. Zweitens: Anonymitätsbehauptungen brauchen einen Testnachweis, keine Annahme. Wer ein Modell als anonymisiert bezeichnet, sollte Resistenztests gegen gängige Angriffsmuster dokumentieren können, bevor eine Behörde danach fragt.
Drittens: Datenminimierung muss in der Architektur sichtbar sein, nicht nur in der Datenschutzerklärung. Das betrifft Feature-Auswahl, Speicherfristen und Zugriffsrechte gleichermassen. Viertens: Die Prüfung, ob eine Datenschutzfolgenabschätzung notwendig ist, sollte standardisiert und wiederholbar sein – nicht als Einzelfallentscheidung eines überlasteten Datenschutzbeauftragten, sondern als fester Bestandteil jedes neuen KI-Projekts. Fünftens: Governance-Strukturen müssen DSGVO- und AI-Act-Anforderungen gemeinsam abbilden, inklusive einer klaren Matrix, wer im Unternehmen welche Rolle nach welchem Rechtsrahmen trägt.
Konkret lässt sich daraus eine Art Mindestcheckliste ableiten, die sich in bestehende Entwicklungsprozesse einfügen lässt:
- Phasenweise Dokumentation von Rechtsgrundlage, Zweck und Massnahmen für Datensammlung, Training, Fine-Tuning, Inferenz und Monitoring
- Nachweisbare Resistenztests gegen Membership-Inference-Angriffe, Modellrekonstruktion und Prompt-Inversion vor jeder Anonymitätsbehauptung
- Standardisierte Prüfroutine, ob eine Datenschutzfolgenabschätzung erforderlich ist, statt Einzelfallentscheidung
- Gemeinsame Rollen- und Verantwortlichkeitsmatrix für DSGVO- und AI-Act-Pflichten
- Regelmässige Aktualisierung der Dokumentation bei jeder wesentlichen Änderung der Modellarchitektur oder Datenbasis
Wer diese Schritte auslässt, spart kurzfristig Aufwand, verlagert das Risiko aber in eine Phase, in der es teurer wird – nämlich in die konkrete Prüfung durch eine Aufsichtsbehörde. Wie schnell aus vollmundigen Sicherheitsversprechen blosses Marketing werden kann, zeigt sich exemplarisch dort, wo der KI-Hype in der Cybersicherheit mehr Erwartungen weckt, als technische Tests am Ende einlösen können. Genau diese Prüfungen werden häufiger, seit die Behörden über konkrete technische Kriterien verfügen, an denen sie sich orientieren können.
Häufige Missverständnisse im Umlauf
In der Debatte um die Sicherheitsanforderungen des EDPB kursieren einige Vereinfachungen, die technisch nicht standhalten. Die Annahme, ein Modell sei anonym, sobald es nur auf anonymisierten Rohdaten trainiert wurde, ist eine davon – das EDPB stellt klar, dass es auf das tatsächliche Modellverhalten und dessen Angriffsresistenz ankommt, nicht auf die Ausgangsdaten allein. Ebenso falsch ist die Vorstellung, EDPB-Leitlinien seien verbindliche Normen im Sinne einer ISO-Zertifizierung. Sie sind Auslegungshilfen ohne eigene Gesetzeskraft, wirken aber faktisch als Referenzrahmen, weil sich Aufsichtsbehörden in ihrer Prüfpraxis daran orientieren.
Ein drittes Missverständnis betrifft das Verhältnis von AI Act und DSGVO: Der AI Act ersetzt die Datenschutz-Grundverordnung nicht, sondern ergänzt sie um Risikoklassen und spezifische Pflichten für KI-Systeme. Wer den AI Act als „neuen Datenschutzrahmen“ verkauft, verkennt, dass die DSGVO für personenbezogene Daten in KI-Systemen vollständig weitergilt – eine Einordnung, die auch in aktuellen Analysen zur KI-Regulierung in der EU immer wieder betont wird. Und schliesslich: Formale Security-Policies ohne technische Tests reichen nicht. Die Leitlinien zu technischen und organisatorischen Massnahmen verlangen explizit nachweisbare Prüfungen der Belastbarkeit und Angriffsresistenz, nicht nur Papierkonzepte.
Ein viertes, subtileres Missverständnis liegt in der Annahme, die neuen Anforderungen richteten sich ausschliesslich an grosse Foundation-Modell-Anbieter. Tatsächlich gelten die Prinzipien der Guidelines 4/2024 grundsätzlich unabhängig von der Modellgrösse. Ein kleines, intern trainiertes Klassifikationsmodell, das personenbezogene Daten verarbeitet, unterliegt denselben Prüflogiken wie ein grosses Sprachmodell – nur dass die Aufsichtsbehörden ihre begrenzten Prüfkapazitäten bislang eher auf sichtbare, öffentlich zugängliche Systeme konzentrieren. Das kann sich verschieben, sobald mehr standardisierte Prüfverfahren verfügbar sind.
Meine Einschätzung: Standardisierung ist überfällig, aber lückenhaft
Ich halte die Entwicklung für richtig, auch wenn sie spät kommt. Zu lange konnten Unternehmen mit vagen Verweisen auf „Privacy by Design“ durchkommen, ohne je zeigen zu müssen, was das technisch bedeutet. Dass das EDPB jetzt konkrete Testverfahren gegen Privacy-Angriffe verlangt, zwingt Entwicklungsteams, Sicherheitsfragen früher im Prozess zu stellen als bisher üblich. Das ist im Kern eine Verschiebung von Vertrauen zu Nachweis – und diese Verschiebung war überfällig, gerade weil generative Modelle zunehmend mit heiklen Datensätzen trainiert werden.
Gleichzeitig bleibt eine entscheidende Frage offen: Wie tief müssen Resistenztests tatsächlich gehen, damit eine Behörde sie akzeptiert? Das EDPB nennt Angriffsklassen, aber keine konkreten Metriken oder Toolvorgaben. Diese Unschärfe ist einerseits nachvollziehbar – ein zu starres Regelwerk würde jede technische Weiterentwicklung sofort veralten lassen. Andererseits schafft sie Rechtsunsicherheit für alle, die es ernst meinen, während Akteure mit laxer Auslegung vorerst ungestraft davonkommen könnten. Ist das der Preis dafür, dass Regulierung mit dem Tempo der KI-Entwicklung überhaupt Schritt halten will?
Ein weiterer Punkt, den ich kritisch sehe: Die Verzahnung von DSGVO- und AI-Act-Prüfung klingt in der Theorie elegant, produziert in der Praxis aber zunächst mehr Aufwand, nicht weniger. Kleinere Unternehmen und Start-ups, die ohnehin knapp bei Compliance-Ressourcen sind, werden diese Doppelbelastung stärker spüren als grosse Konzerne mit eigenen Rechtsabteilungen. Die Standardisierung schützt Betroffene – sie verschärft aber auch die Marktkonzentration zugunsten jener, die sich Compliance leisten können.
Was bleibt?
Die technische Standardisierung durch das EDPB verschiebt die Beweislast: weg von Absichtserklärungen, hin zu dokumentierten Tests und modularer Architektur. Für Verantwortliche in Unternehmen heisst das, Datenschutz nicht mehr am Ende eines KI-Projekts einzubauen, sondern als festen Bestandteil jeder einzelnen Verarbeitungsphase zu denken. Die offenen Fragen zur genauen Prüftiefe werden nicht durch Warten kleiner, sondern durch eigene Dokumentation und frühzeitige Auseinandersetzung mit den Opinion 28/2024 des EDPB. Wer jetzt noch auf eine finale, gerichtsfeste Definition von Anonymität wartet, wird von der Aufsichtspraxis überholt – nicht von der Theorie. Eine rechtliche Einordnung der Folgen dieser Opinion zeigt, wie sehr sich die Anforderungen an technische Dokumentation bereits verschärft haben. Die eigentliche Frage für die kommenden Monate lautet: Werden nationale Aufsichtsbehörden diese Vorgaben tatsächlich konsequent durchsetzen – oder bleibt es, wie so oft, bei einer Zusammenfassung der Guidelines 4/2024 ohne spürbare Prüfpraxis?



Was halten Sie von dem Thema? Hier können Sie mit anderen Leserinnen und Lesern ins Gespräch gehen.
Mitreden & diskutieren
Ihre Meinung zählt — teilen Sie Gedanken, Fragen oder Erfahrungen zu diesem Artikel.