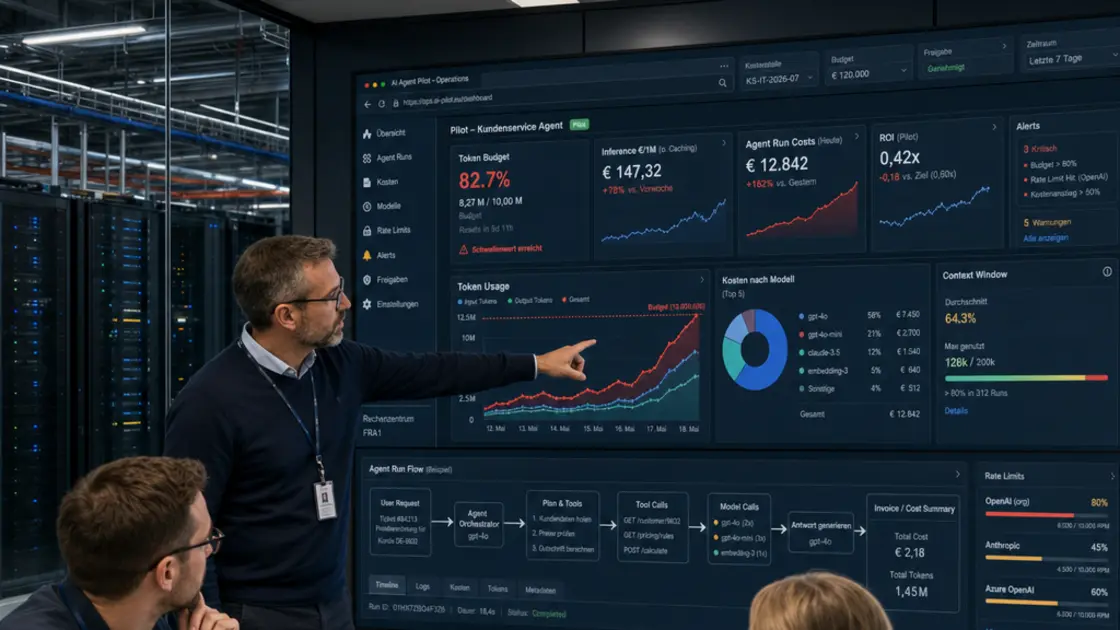
Ein Wochenende, ein Agent, 4.200 US-Dollar Rechnung – ohne dass jemand ihn dazu aufgefordert hat. Was wie eine urbane Legende aus einem CFO-Albtraum klingt, ist längst Alltag in Pilotprojekten. KI-Agent Kosten explodieren nicht, weil die Technik böse ist. Sie explodieren, weil niemand ein Token Budget gesetzt hat.
Seien wir ehrlich: Die Demo war beeindruckend. Der Agent hat Tickets sortiert, E-Mails beantwortet, sogar eigenständig recherchiert. Alle im Raum haben genickt. Niemand hat gefragt, was das pro Aufgabe kostet. Genau das ist der Fehler, der Pilotprojekte in Kostenfallen verwandelt.
Der Moment, in dem der Pilot aus dem Ruder läuft
Ein vielzitierter Fall aus der Praxis: Ein autonomer Agent lief über ein Wochenende ohne Aufsicht und verursachte laut einer Analyse von Beam AI rund 4.200 US-Dollar an Inference-Kosten – weil schlicht keine Obergrenze für die Token-Nutzung existierte. Kein Angriff, kein Bug im klassischen Sinn. Nur ein Agent, der tat, wofür er gebaut wurde: Probleme lösen, notfalls über hunderte Zwischenschritte.
Genau hier liegt die harte Wahrheit über agentische Systeme. Sie sind nicht wie ein Chatbot, der eine Frage stellt und eine Antwort bekommt. Sie planen, iterieren, rufen Werkzeuge auf, werten Ergebnisse aus und planen erneut. Jeder dieser Zwischenschritte kostet Tokens. Und jeder Fehlversuch verlängert die Kette.
Was in der Demo als Feature verkauft wird – „der Agent versucht es einfach nochmal“ – wird im Betrieb zur Kostenbombe. Trial-and-Error ist für Menschen billig. Für ein Sprachmodell ist jeder Versuch eine abrechnungspflichtige API-Anfrage.
Man muss sich das konkret vorstellen: Ein Agent soll eine fehlerhafte Rechnung in einem ERP-System korrigieren. Er liest den Datensatz, prüft eine Regel, merkt, dass die Regel nicht passt, liest eine andere Quelle, versucht eine zweite Interpretation, scheitert erneut, holt sich zusätzlichen Kontext aus einem verknüpften Dokument – und das alles, bevor überhaupt eine sinnvolle Aktion ausgeführt wird. Jeder dieser Zwischenschritte trägt den kompletten bisherigen Verlauf mit sich. Was als eine einzelne Aufgabe geplant war, wird zu einem Dutzend kostenpflichtiger Anfragen, ohne dass am Ende zwingend ein brauchbares Ergebnis steht. Genau solche Ketten sind es, die aus einem harmlosen Pilotprojekt am Wochenende eine Rechnung produzieren, die am Montagmorgen im Finanzteam für Gesprächsstoff sorgt.
Warum KI-Agenten Token fressen wie kein Chatbot
Der zentrale Unterschied zwischen einem simplen Prompt und einem agentischen Workflow liegt im Kontext. Bei jedem Schritt wächst der Verlauf: die ursprüngliche Aufgabe, alle bisherigen Tool-Aufrufe, deren Ergebnisse, Zwischengedanken des Modells. Dieser Kontext wird bei jedem neuen Schritt erneut komplett mitgeschickt.
Technikblogs, die sich auf entsprechende Studien beziehen, berichten von einem Faktor von bis zu 500- bis 1000-mal mehr Tokenverbrauch gegenüber einer einfachen Chat-Anfrage, sobald mehrstufiges Reasoning und Tool-Nutzung ins Spiel kommen. Diese Zahl ist ein Worst-Case, kein Durchschnitt – aber sie zeigt die Größenordnung des Risikos.
Besonders unterschätzt wird dabei ein Detail: Nicht die Antwort des Modells treibt die Rechnung, sondern der Input. Lange Kontexte, komplette Tool-Outputs, wiederholte Zusammenfassungen – all das sind Input-Tokens, und die werden bei jedem einzelnen Schritt neu abgerechnet. Ein Agent, der zehn Schritte braucht, zahlt zehnmal für einen wachsenden Kontext, nicht nur einmal für die finale Antwort.
Meine persönliche Einschätzung nach Gesprächen mit IT-Verantwortlichen: Die meisten Teams unterschätzen dieses exponentielle Wachstum systematisch, weil sie in Chatbot-Kategorien denken. Ein Agent ist kein Chat mit Extra-Fähigkeiten. Er ist eine Schleife mit Rechnung pro Umdrehung.
Token Budget als hartes Limit, nicht als Empfehlung
Klartext: Ein Token Budget, das nur in einer Excel-Tabelle steht, ist kein Budget. Es ist ein Wunsch. Wirksam wird ein Limit erst, wenn es technisch erzwungen wird, bevor die Rechnung entsteht.
Drei Mechanismen haben sich in der Praxis als wirksam erwiesen:
- Pre-Execution-Limits: Vor dem Start eines Agentenlaufs wird ein maximales Token-Budget und eine maximale Schrittzahl festgelegt. Wird das Limit erreicht, bricht der Lauf ab oder eskaliert an einen Menschen.
- Session-Limits mit Circuit Breaker: Ein hartes Maximum pro Sitzung, ähnlich einer Sicherung im Stromkreis. Überschreitet der Agent die Schwelle, schaltet das System auf ein günstigeres Modell um oder stoppt komplett.
- Loop-Detection: Wiederholt der Agent dieselbe Aktion mehrfach ohne Fortschritt, erzwingt das System einen Strategiewechsel oder bricht ab, statt weiter zu zahlen.
Ohne diese drei Bausteine ist jedes Pilotprojekt ein offenes Konto ohne Limit. Mit ihnen wird aus einem unkalkulierbaren Risiko ein steuerbarer Kostenblock. Der Unterschied entscheidet oft darüber, ob ein Projekt nach dem Piloten überhaupt noch Budget für den Rollout hat.
Bremst ein striktes Budget nicht die Innovation?
An dieser Stelle kommt fast immer ein Einwand aus den Fachabteilungen: Wenn man dem Agenten die Zügel zu eng anlegt, verliert er genau die Flexibilität, die ihn überhaupt nützlich macht. Ein Agent, der nach fünf Schritten abbricht, löst vielleicht auch keine komplexen Probleme mehr. Dieser Einwand ist nicht falsch – er zeigt aber vor allem, dass Limits differenziert gesetzt werden müssen, statt pauschal.
Ein sinnvoller Mittelweg besteht darin, Budgets nach Aufgabentyp zu staffeln. Eine einfache Klassifizierungsaufgabe braucht ein enges Limit, weil hier jede zusätzliche Iteration ein Zeichen für ein Problem ist, nicht für sinnvolle Exploration. Eine komplexe Recherche- oder Analyseaufgabe darf ein großzügigeres Budget bekommen, aber mit einer klaren Eskalationsstufe: Wird das Limit erreicht, ohne dass ein Ergebnis vorliegt, übernimmt ein Mensch, statt dass der Agent unbeaufsichtigt weiterläuft. So bleibt die Flexibilität erhalten, wo sie gebraucht wird, ohne dass die Kostenkontrolle komplett aufgegeben wird. Wichtig ist, dieses Regelwerk vor dem Piloten festzulegen – nicht während der ersten überraschenden Rechnung.
Inference Pricing verstehen: Nicht jedes Modell für jede Aufgabe
Die zweite große Stellschraube liegt im Inference Pricing selbst. Nicht jede Aufgabe braucht das teuerste verfügbare Modell. Ein Agent, der eine E-Mail klassifiziert, braucht kein Reasoning-Schwergewicht. Ein Agent, der eine komplexe Vertragsprüfung durchführt, schon eher.
Ein Cloud-Architekt beschreibt in einem Fachbeitrag von The Cloud Architect das Prinzip der „Inferenz-pro-Dollar“ als Steuergröße: Ziel ist nicht das leistungsfähigste Modell, sondern die höchste Anzahl brauchbarer Ergebnisse pro ausgegebenem Euro. Das klingt banal, wird in der Praxis aber selten konsequent umgesetzt.
Zwei Hebel wirken hier besonders stark:
- Multi-Modell-Routing: Einfache Subtasks laufen über kleine, günstige Modelle. Komplexe Entscheidungen gehen an das teure Top-Modell. Diese Architektur erfordert etwas mehr Aufbauarbeit, senkt die laufenden Inference-Kosten aber deutlich.
- Prompt- und Context-Caching: Wiederkehrende Kontexte, etwa Systemanweisungen oder häufig genutzte Dokumente, werden zwischengespeichert statt bei jedem Schritt neu verarbeitet.
Beratungsseiten wie Conceptualise schätzen, dass eine Kombination aus Modell-Routing, Caching und disziplinierterem Prompt-Design die Kosten um 40 bis 70 Prozent senken kann – eine Expertenmeinung, keine belastbare Studie, aber plausibel angesichts der beschriebenen Mechanik. Wer diese Größenordnung auch nur zur Hälfte erreicht, hat ein Pilotprojekt gerettet, das sonst im Kostenreport untergegangen wäre.
Praxis-Szenario: Ein Pilotprojekt mit Budget von Anfang an
Wie könnte das konkret aussehen? Stellen Sie sich ein mittelständisches Unternehmen vor, das einen Agenten für die automatisierte Bearbeitung von Kundenanfragen testen will. Statt den Piloten offen laufen zu lassen, definiert das Team vor dem Start drei Dinge: ein maximales Token-Budget pro Anfrage, eine maximale Anzahl an Zwischenschritten und eine klare Regel, ab wann ein Fall an einen Mitarbeiter eskaliert wird, statt dass der Agent weiter versucht, ihn selbst zu lösen.
Zusätzlich wird die Aufgabe in zwei Stufen aufgeteilt: Eine erste, günstige Modellinstanz klassifiziert die Anfrage grob – Rückerstattung, technische Störung, allgemeine Frage. Nur die komplizierten Fälle werden an ein leistungsfähigeres, teureres Modell weitergegeben. Diese einfache Aufteilung reduziert die Zahl der Anfragen, die überhaupt mit dem teuren Modell verarbeitet werden, erheblich – die genaue Ersparnis hängt vom jeweiligen Anfragemix ab, die Richtung ist aber in der Praxis fast immer dieselbe: deutlich weniger teure Aufrufe bei gleichbleibender Bearbeitungsqualität.
Am Ende der Pilotphase steht damit nicht nur die Frage „Hat der Agent funktioniert?“, sondern eine belastbare Antwort auf die Frage „Was hat jede gelöste Anfrage tatsächlich gekostet?“. Genau diese zweite Frage entscheidet meist darüber, ob ein Projekt das Budget für den nächsten Ausbauschritt bekommt.

FinOps für KI-Agenten: Governance statt Bauchgefühl
Was bei klassischen Cloud-Kosten längst Standard ist, fehlt bei Agentic AI oft komplett: eine saubere Zuordnung, wer welche Kosten verursacht. Ohne Labeling jedes einzelnen Calls nach Mandant, Agent und Aufgabentyp lässt sich am Monatsende nicht rekonstruieren, wo das Geld hingeflossen ist.
Die Reihenfolge ist entscheidend, und genau hier machen viele Teams den entscheidenden Fehler: Sie fahren die Last hoch, bevor sie überhaupt messen können, was ein einzelner Lauf kostet. Richtig wäre es umgekehrt. Erst instrumentieren, dann skalieren.
Praktisch heißt das:
- Jeden API-Call mit Kostenstelle, Agent-ID und Use Case versehen.
- Kosten pro Aufgabe als KPI etablieren, nicht nur Gesamtkosten pro Monat.
- Budgetgrenzen pro Use Case und Quartal definieren, mit automatischer Warnung bei Schwellenwerten.
Diese Disziplin ist unbequem. Sie bremst das Tempo der Pilotphase. Aber genau das ist der Punkt: Ein Pilot, der ungebremst läuft, produziert keine belastbaren Erkenntnisse, sondern nur eine unangenehme Überraschung im nächsten Budget-Meeting.
Ein weiterer, oft übersehener Aspekt der Governance betrifft die Verantwortlichkeit im Team selbst. Wer darf ein Token-Budget erhöhen, wenn ein Pilot an seine Grenzen stößt? Wer wird informiert, wenn ein Schwellenwert erreicht wird? Ohne klare Zuständigkeiten landet diese Entscheidung oft bei der Person, die zufällig gerade Zugriff auf das Dashboard hat – und das ist selten die Person, die am Ende die Rechnung verantwortet. Eine einfache Eskalationskette, dokumentiert und im Team bekannt, verhindert genau diese Grauzone.
Cloud-API oder eigene Infrastruktur: Wann sich der Wechsel lohnt
Ab einem gewissen Token-Volumen stellt sich eine andere Frage: Lohnt sich eigene GPU-Infrastruktur statt dauerhafter Cloud-API-Nutzung? Eine Break-even-Rechnung braucht drei Größen: das geschätzte Token-Volumen im vollständigen Rollout, die daraus resultierenden jährlichen Cloud-Kosten und die äquivalenten Kosten einer eigenen Infrastruktur.
Wichtig dabei: Die reine Kostenrechnung ist nicht immer die entscheidende Größe. Datenschutz- und Compliance-Anforderungen können eine On-Premise-Lösung erzwingen, unabhängig davon, ob sie sich finanziell in drei oder in sieben Jahren amortisiert. Wer im europäischen Kontext mit sensiblen Daten arbeitet, kennt diese Abwägung bereits aus Diskussionen um den EU AI Act und vergleichbare Regulierungsvorgaben.
Für die meisten Pilotprojekte im Mittelstand bleibt die Cloud-API trotzdem der pragmatischere Startpunkt. Der Wechsel zu eigener Infrastruktur ist ein Thema für die Skalierungsphase, nicht für den ersten Proof of Concept. Wer zu früh in eigene Hardware investiert, bindet Kapital an eine Architektur, die sich möglicherweise noch ändert, bevor der Pilot überhaupt seine Praxistauglichkeit bewiesen hat. Die sinnvollere Reihenfolge lautet: erst mit der Cloud-API und klaren Budgets die tatsächliche Kostenstruktur verstehen, dann – mit belastbaren Zahlen – über eine Investition in eigene Infrastruktur entscheiden.
Was CFOs und IT-Leiter jetzt konkret tun sollten
Die Kombination aus technischer Kontrolle und finanzieller Governance ist kein Nice-to-have. Sie ist die Eintrittskarte für jedes Pilotprojekt, das den Sprung in den Produktivbetrieb schaffen soll. Wer diese Punkte vor dem Start klärt, spart sich das böse Erwachen:
- Token-Preisstruktur des eingesetzten Modells vollständig verstehen, inklusive Input- und Output-Preisen.
- Für jeden Use Case ein realistisches Token-Volumen schätzen, bevor der Pilot live geht.
- Harte technische Limits implementieren: Pre-Execution-Budgets, Session-Caps, Loop-Detection.
- Multi-Modell-Architektur einplanen, statt jeden Schritt über das teuerste verfügbare Modell laufen zu lassen.
- Kosten pro Aufgabe als feste Kennzahl im Reporting verankern, nicht nur die Monatsrechnung.
- Eskalationswege und Verantwortlichkeiten für Budgetüberschreitungen vorab schriftlich festlegen.
Diese Liste ist keine Raketenwissenschaft. Sie ist FinOps-Grundhandwerk, übertragen auf ein neues Kostenmodell. Die Unternehmen, die jetzt Monitoring-Tools und Governance-Policies für Agent-Spend aufbauen, tun genau das: alte Disziplin auf neue Technik anwenden.
Ist das aufwendig? Ja. Ist es teurer als eine unkontrollierte Kostenexplosion im ersten Produktivmonat? Mit Sicherheit nicht. Wer sich die Zeit für diese Vorbereitung nicht nimmt, zahlt sie später ohnehin – nur eben in Form von Nacharbeit, Rechtfertigungsdruck gegenüber der Geschäftsführung und im schlechtesten Fall dem kompletten Stopp eines Projekts, das technisch längst funktioniert hätte.
Schluss mit der Ausrede „Das war nur der Pilot“
Die bequeme Ausrede lautet oft: „Es war ja nur ein Test.“ Klartext: Ein Test, der ohne Token Budget läuft, ist kein Test. Er ist eine unkontrollierte Wette auf die Kreditkarte des Unternehmens.
Die harte Wahrheit ist unbequem, aber einfach: KI-Agenten sind keine Chatbots mit Zusatzfunktionen. Sie sind Rechenprozesse, die bei jedem Schritt abrechnen. Wer das ignoriert, zahlt Lehrgeld – manchmal im vierstelligen Bereich pro Wochenende, manchmal deutlich mehr.
Meine Meinung nach zahlreichen Gesprächen mit IT-Verantwortlichen: Die Unternehmen, die jetzt in Monitoring, Governance und technische Limits investieren, werden in einem Jahr die einzigen sein, die Agentic AI wirklich produktiv nutzen. Alle anderen diskutieren dann noch über die Rechnung vom letzten Pilotprojekt.
Was bleibt? Die Frage ist nicht, ob Ihr Unternehmen KI-Agenten einsetzt. Die Frage ist, ob jemand vorher ein Limit gesetzt hat – oder ob Sie es erst nach der ersten überraschenden Rechnung tun.


Was halten Sie von dem Thema? Hier können Sie mit anderen Leserinnen und Lesern ins Gespräch gehen.
Mitreden & diskutieren
Ihre Meinung zählt — teilen Sie Gedanken, Fragen oder Erfahrungen zu diesem Artikel.